揭秘DeepSeek R1-Zero训练方式,GRPO还有极简改进方案
揭秘DeepSeek R1-Zero训练方式,GRPO还有极简改进方案其实大模型在DeepSeek-V3时期就已经「顿悟」了?
来自主题: AI技术研报
11549 点击 2025-03-22 15:46
 搜索
搜索
其实大模型在DeepSeek-V3时期就已经「顿悟」了?

一个超越DeepSeek GRPO的关键RL算法出现了!这个算法名为DAPO,字节、清华AIR联合实验室SIA Lab出品,现已开源。禹棋赢,01年生,本科毕业于哈工大,直博进入清华AIR,目前博士三年级在读。去年年中,他以研究实习生的身份加入字节首次推出的「Top Seed人才计划」。

DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

没有任何冷启动数据,7B 参数模型能单纯通过强化学习学会玩数独吗?

开源微调神器Unsloth带着黑科技又来了:短短两周后,再次优化DeepSeek-R1同款GRPO训练算法,上下文变长10倍,而显存只需原来的1/10!
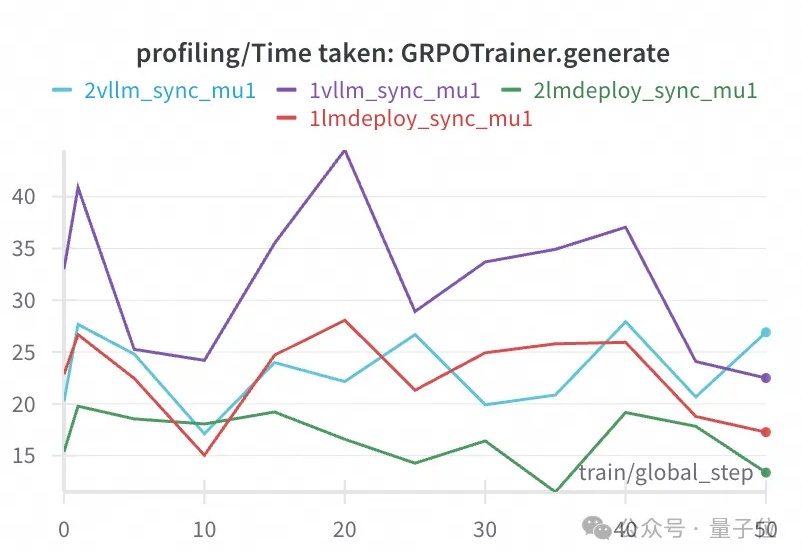
GRPO训练又有新的工具链可以用,这次来自于ModelScope魔搭社区。
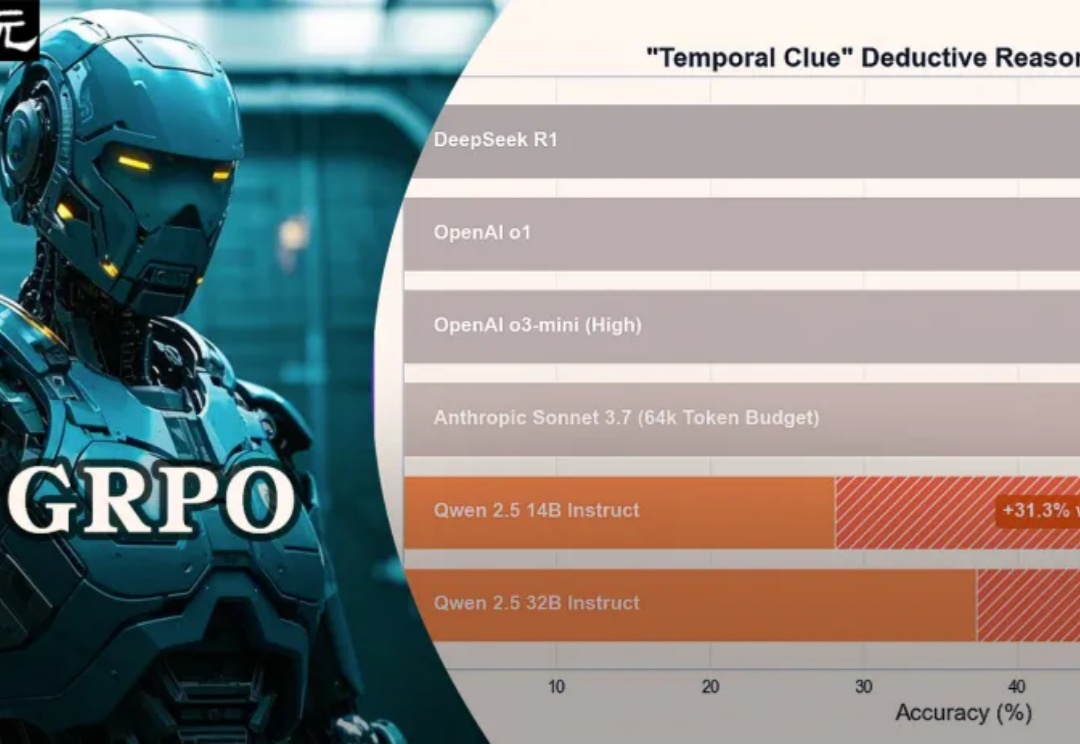
32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。
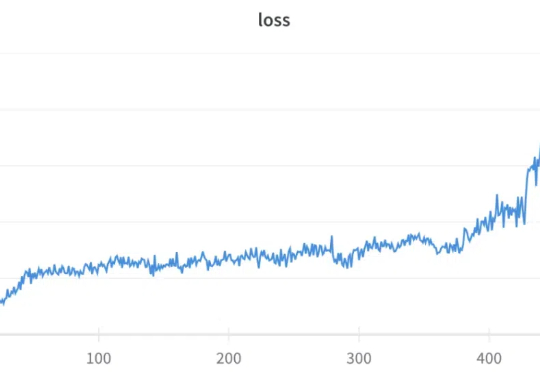
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。
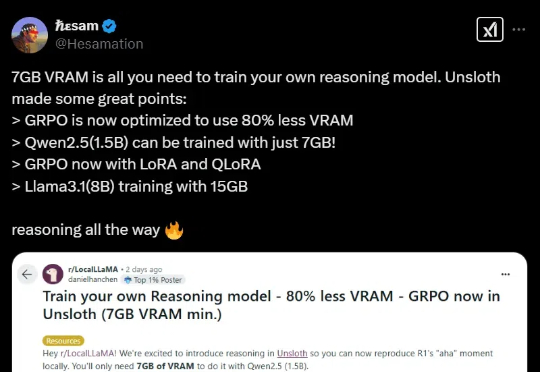
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。