
UPenn提出Graph of Skills:把海量Skill连成技能图 |CC可用、支持Minimax2.7
UPenn提出Graph of Skills:把海量Skill连成技能图 |CC可用、支持Minimax2.7很多人以为,给Agent装上更多Skill,它就会变得更强。
来自主题: AI技术研报
8547 点击 2026-04-17 09:11
 搜索
搜索
很多人以为,给Agent装上更多Skill,它就会变得更强。

据知情人士透露,一家从哈佛大学独立出来的新型人工智能实验室正在与投资者进行谈判,以筹集约1 亿美元,以追求一项听起来像科幻小说的使命 :"一个人类可以记住一切的世界"。
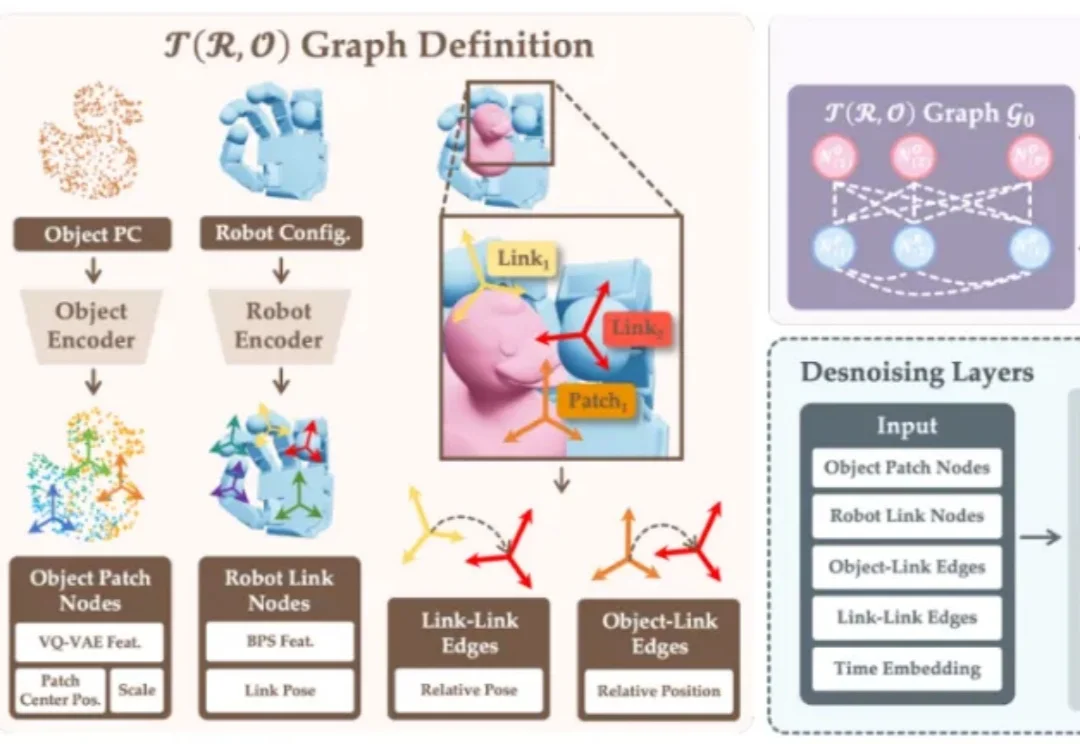
T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。

每月5美刀,就能在你家服务器里养个AI打工人,无缝接入Telegram、Discord、Slack、飞书、企业微信等平台。它不仅能帮你干活,还会自己攒技能并反哺训练。网友直呼:换掉OpenClaw太爽了!

我认真看 Hermes Agent,不是因为它2.9万Star,而是因为那条 hermes claw migrate。一个新框架敢把"把旧用户整套资产搬过来"做成默认入口,这事本身就很说明问题。
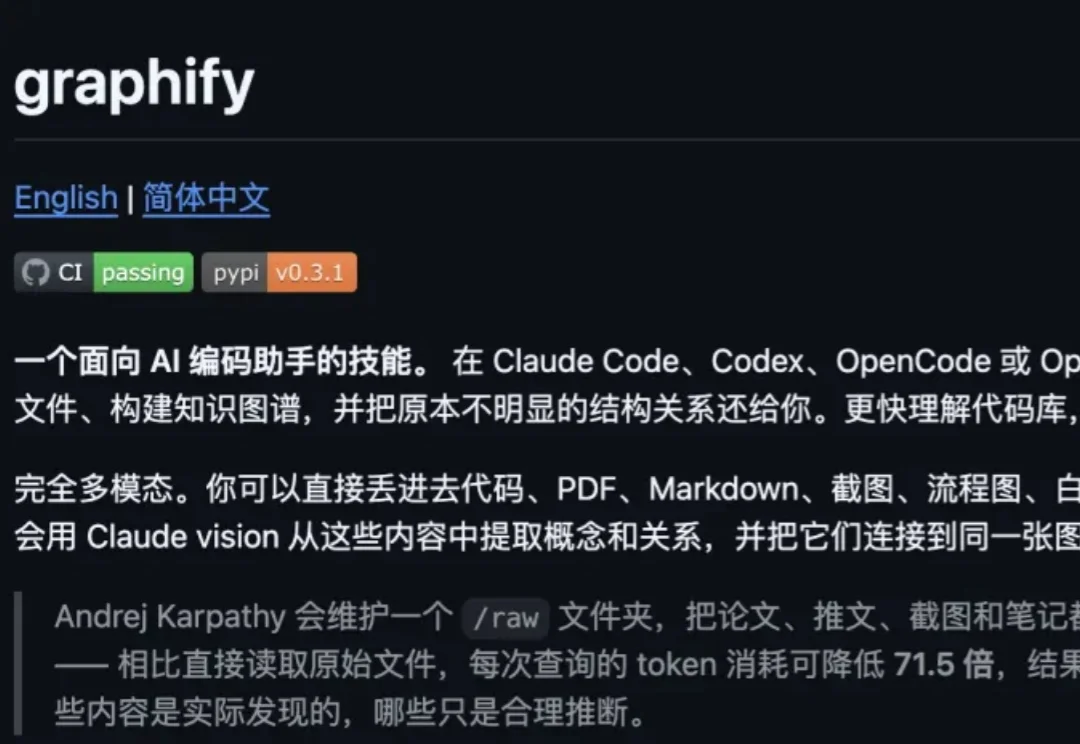
AI圈的节奏已经快到让人产生幻觉了。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
Granola 最初是一款面向专业消费者的应用,安装在用户电脑上,用于转录会议并生成笔记。如今,它一直在开发功能以适应企业级技术栈。例如,去年它开始允许团队成员协作处理笔记。公司表示,目前已成功打入 Vanta、Gusto、Thumbtack、Asana、Cursor、Lovable、Decagon 以及 Mistral AI 等企业客户。
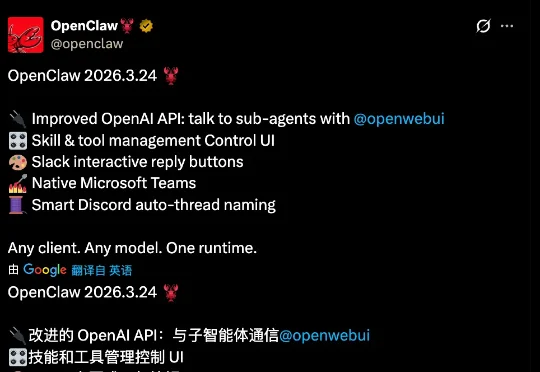
OpenClaw 又开始日更了:Skills 安装终于不用自己猜缺什么了,系统会手把手告诉你下一步;控制台界面也大改,找东西不再像在迷宫里转。另外堵上了一个文件访问的安全漏洞,Telegram、Discord、WhatsApp 的频道 bug 也扫了一轮。