
训练一次经历 419 次意外故障,英伟达 GPU 也差点玩不转 405B 模型,全靠 Meta 工程师后天救场
训练一次经历 419 次意外故障,英伟达 GPU 也差点玩不转 405B 模型,全靠 Meta 工程师后天救场一半以上的故障都归因于 GPU 及其高带宽内存。
来自主题: AI资讯
6780 点击 2024-07-29 17:47
 搜索
搜索
一半以上的故障都归因于 GPU 及其高带宽内存。

英特尔用“光”,突破了大模型时代棘手的算力难题—— 推出业界首款全集成OCI(光学计算互连)芯片。
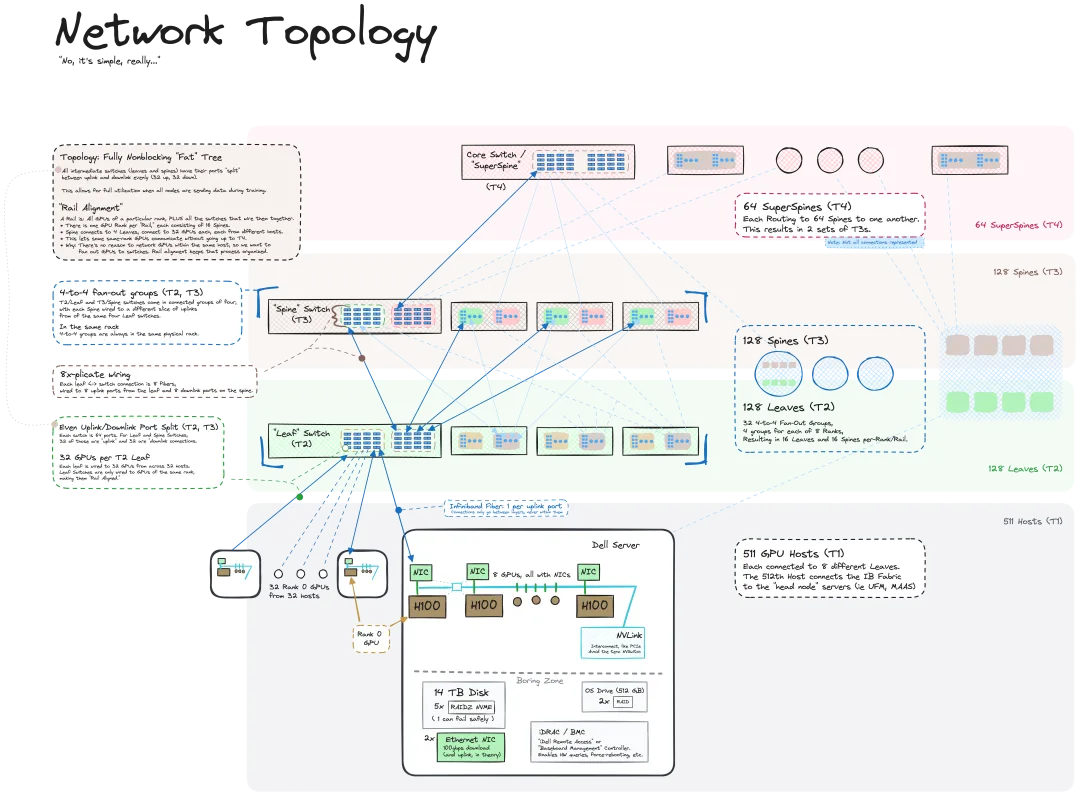
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。

英伟达全面转向开源GPU内核模块,历史将再次见证Linux社区开源的力量。

时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。
囤 GPU 真的像修铁路一样,是一项划算的投资吗?

纯国产GPU的万卡集群,它来了! 而且还是国内首个全功能GPU,兼容CUDA的那种。

Scaling Law 持续见效,让算力就快跟不上大模型的膨胀速度了。「规模越大、算力越高、效果越好」成为行业圭皋。主流大模型从百亿跨越到 1.8 万亿参数只用了1年,META、Google、微软这些巨头也从 2022 年起就在搭建 15000 卡以上的超大集群。「万卡已然成为 AI 主战场的标配。」

AI基础设施的巨额投资,和实际的AI生态系统实际收入之间,差距已经到了不可思议的地步。曾经全球AI面临的2000亿美元难题,如今已经翻成了6000亿美元。

全美TOP 5的机器学习博士痛心发帖自曝,自己实验室里H100数目是0!这也引起了ML社区的全球网友大讨论。显然,相比普林斯顿、哈佛这样动辄三四百块H100的GPU大户,更常见的是GPU短缺的「穷人」。同一个实验室的博士,甚至时常会出现需要争抢GPU的情况。