DeepSeek新模型上线!引入DSA新稀疏注意力,还又狙了CUDA一枪
DeepSeek新模型上线!引入DSA新稀疏注意力,还又狙了CUDA一枪刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
来自主题: AI资讯
11284 点击 2025-09-29 19:04
 搜索
搜索
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
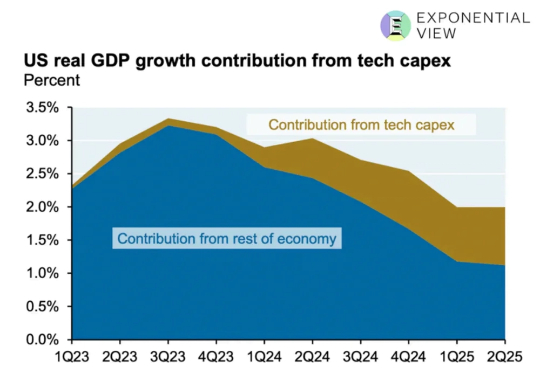
AI投资热潮是否形成泡沫?作者提出一个实用框架,用五个指标(经济压力、行业压力、收入增长、估值热度、资金质量)分析当前状况,对比铁路、电信和互联网历史泡沫。结论显示AI投资尚未泡沫,属于需求驱动的繁荣,但需警惕GPU快速折旧和数据中心融资风险。未来需监控收入增长是否能持续覆盖投资。

手机PC等终端芯片,在Agent变革面前也要被重塑了。面向PC,高通首次推出专为超高端PC打造的骁龙X2 Elite Extreme,目标是“轻松驾驭智能体AI体验”;
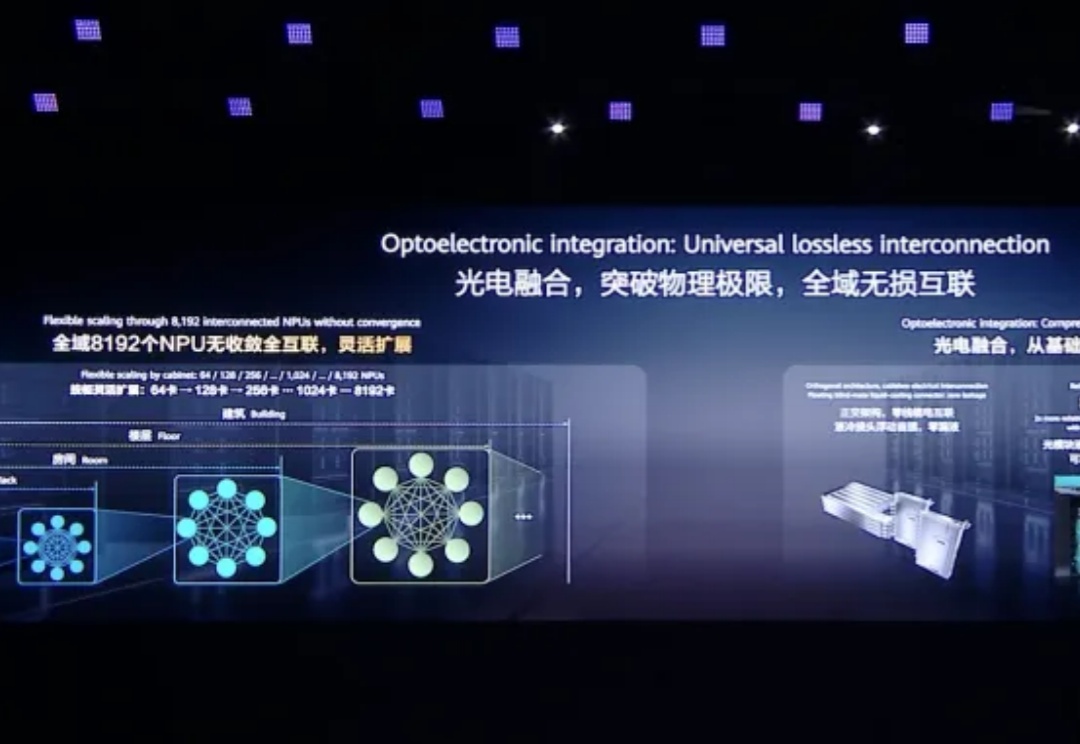
上周,华为全联接大会集中展示了华为最新最强的一系列创新。

当芯片像炉子一样发烫,电费狂飙、延迟卡顿、服务掉链子,所有想象中的未来都会被「热」锁死。微软这次亮出的杀手锏,是在芯片里开出液体血管,让冷却液直达发热核心。这AI能不能继续狂奔,价格能不能压住,体验能不能丝滑,都系于这场降温革命。

美国时间 9 月 22 日,北京时间 9 月 23 日凌晨,英伟达和 OpenAI 突然宣布战略合作伙伴和重大投资。

最新消息,英伟达计划向OpenAI投资最高1000亿美元,OpenAI则要用这笔钱构建至少10GW的AI数据中心,全用英伟达的系统。10GW,相当于400-500万个GPU了,并且,黄仁勋8月份曾表示,建成1GW的数据中心的成本大约在500-600亿美元。
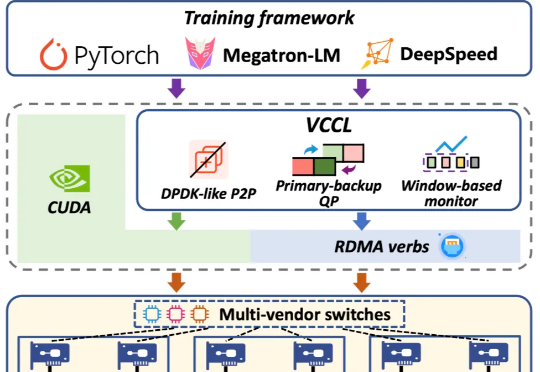
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。

刚刚,芯片圈大地震,英伟达将斥资50亿美元入股英特尔,一举成为大股东!英伟达出钱,英特尔出力!英特尔将为英伟达定制AI数据中心所需的x86 CPU,未来还将推出集成英伟达GPU的系统级芯片。
马斯克“巨硬计划”(MACROHARD)新动作曝光: 6个月从0建起算力集群,已完成200MW供电规模,足以支持11万台英伟达GB200 GPU NVL72。仅用6个时间,完成了OpenAI和甲骨文等合作花费15个月完成的工作,再次创造纪录。