
全自研仿真GPU求解器x虚实对标物理测量工厂,打造具身合成数据SuperApp,加速具身仿真生态丨光轮智能@MEET2026
全自研仿真GPU求解器x虚实对标物理测量工厂,打造具身合成数据SuperApp,加速具身仿真生态丨光轮智能@MEET2026从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。
来自主题: AI资讯
9196 点击 2025-12-23 10:06
 搜索
搜索
从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。

这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
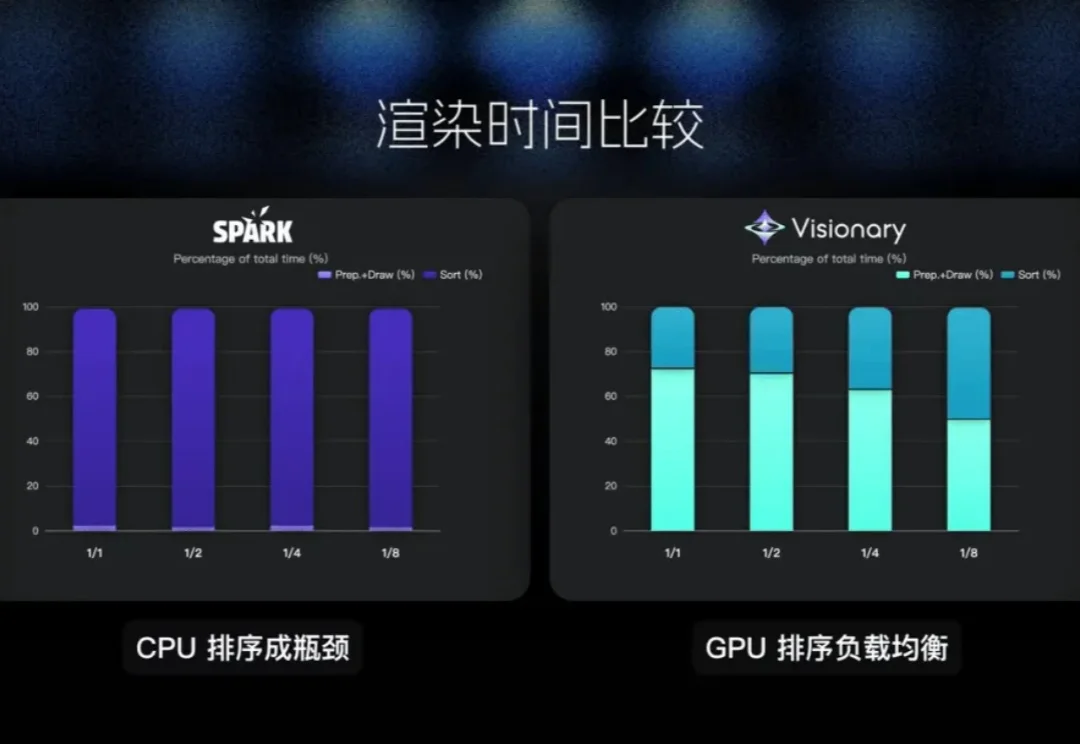
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。

当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?
游戏&装机党注意了!

他们不光能造GPU,还能写出全球顶级的算法!摩尔线程这次开源给国产具身智能递了一把「神兵利器」。

昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。原因不明。论文中,苹果揭示了他们开发的一个基于 TPU 的可扩展 RL 框架 RLAX。是的,你没有看错,不是 GPU,也不是苹果自家的 M 系列芯片,而是谷歌的 TPU!还不止如此,这篇论文的研究中还用到了亚马逊的云和中国的 Qwen 模型。

AI真的上天了。

面对谷歌TPU的攻势,英伟达开始紧张了。
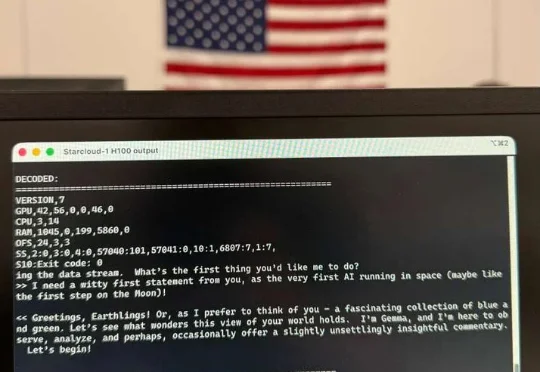
见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。