一文看懂AI竞赛:王座更替,谁家的AI更招财
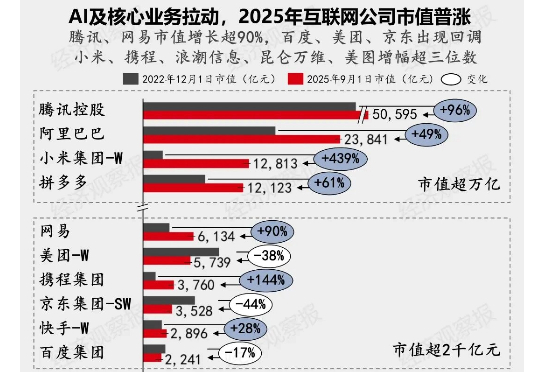
一文看懂AI竞赛:王座更替,谁家的AI更招财对比2022年11月底,ChatGPT横空出世时,头部科技公司市值变化:前两名未变,第三至十位座次更替。腾讯稳居第一,市值上涨约90%至5万亿元;阿里重回2万亿元大关;小米受汽车等新业务带动,市值暴涨439%,跃升至第三,跻身“两万亿俱乐部”。
来自主题: AI资讯
9538 点击 2025-09-04 11:55
 搜索
搜索
对比2022年11月底,ChatGPT横空出世时,头部科技公司市值变化:前两名未变,第三至十位座次更替。腾讯稳居第一,市值上涨约90%至5万亿元;阿里重回2万亿元大关;小米受汽车等新业务带动,市值暴涨439%,跃升至第三,跻身“两万亿俱乐部”。

OpenAI近期动作频频。首先斥巨资收购实验平台Statsig,并任命创始人Vijaye Raji为应用部门新CTO。同时还启动了「OpenAI for Science」项目,致力于打造AI驱动的科学发现平台,以加速基础科学突破。
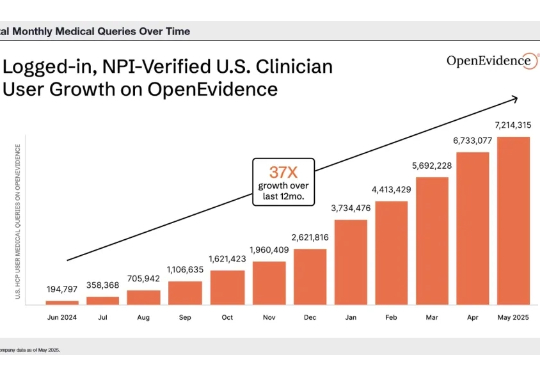
AI医疗领域,冲出一匹年度黑马! 据外媒报道,美国AI医疗初创公司OpenEvidence正在寻求新一轮融资,估值约60亿美元(约合人民币427亿元)。
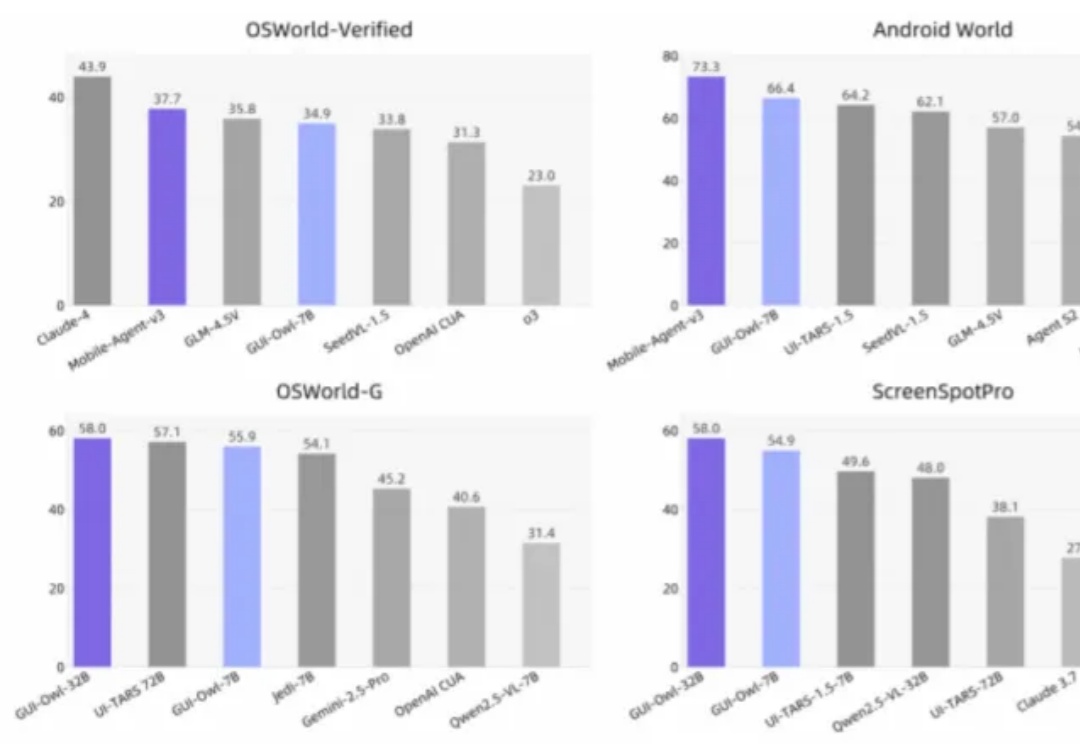
覆盖桌面、移动和 Web,7B 模型超越同类开源选手,32B 模型挑战 GPT-4o 与 Claude 3.7,通义实验室全新 Mobile-Agent-v3 现已开源。

一群AI玩狼人杀,GPT-5断崖式领先,胜率达到了惊人的96.7%。 OpenAI的总裁格雷格·布罗克曼转发了这样的一个基准测试:让7个强大的LLMs,包括开源和闭源,玩了210场完整的狼人杀。
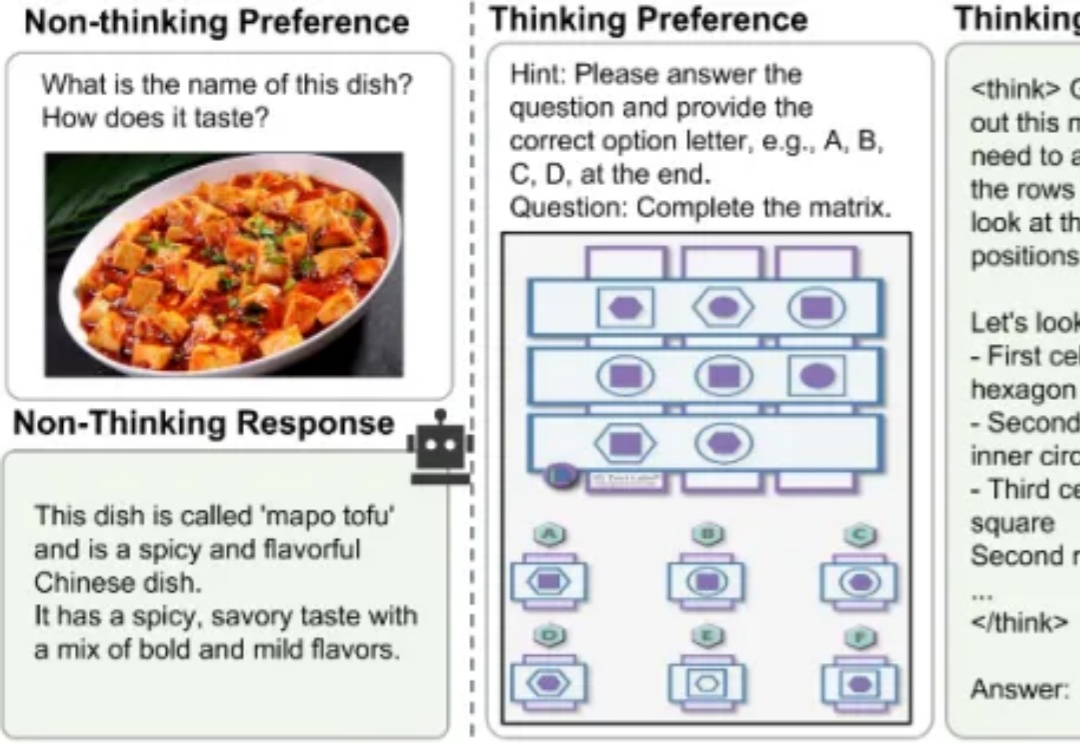
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。

GPT-4o发布才过去半年,Nano Banana这种「下一代」的生图模型就出来了。 这难道是AI界的摩尔定律?不敢想再过半年后,会是什么样的「魔鬼级」生图模型来屠Nano Banana

如今,人工智能已经成为科技发展的主流,尤其是 ChatGPT 问世以来,大语言模型(LLM)正在深刻影响社会、企业和个人的方方面面。

人类心理学说服策略可以有效迁移至LLM 你有没有试过让ChatGPT骂你一句?(doge) 它大概率会礼貌拒绝:私密马赛,我不能这样做orz 但最新研究表明,只需要擅用一点人类的心理技巧PUA,AI就会乖乖(骂你)听话。
退休经济学教授用一个简单问题干懵GPT-5,其拉胯表现与奥特曼口中“博士级AI”的宣传大相径庭。