
AI狼人杀终极决战!GPT、Qwen、DeepSeek大乱斗,人类高玩汗流浃背
AI狼人杀终极决战!GPT、Qwen、DeepSeek大乱斗,人类高玩汗流浃背我真栓Q了!围观了场狼人杀,看得我汗流浃背……
来自主题: AI资讯
7674 点击 2025-12-23 15:25
 搜索
搜索
我真栓Q了!围观了场狼人杀,看得我汗流浃背……

ChatGPT 现在可以由用户主动调整热情程度,例如更加温和体贴和使用更多表情符号等。新个性化选项包括温和体贴、热情洋溢、标题列表和表情符号,用户可以在个性化设置中主动控制这些选项例如减少或增加使用表情符号等。

如果说过去几年,高校还在争论“学生能不能用 ChatGPT 写作业”,那么普渡大学已经直接跳到了下一个阶段:不懂 AI,可能毕不了业。
过去两年,我们几乎默认了一件事: 人和 AI 的交互就只能靠文本框和语音。 不管是 GPT、DeepSeek、Claude,还是各种音视频 Agent,核心入口几乎清一色是一个聊天框。 但只要你真正做

在AI席卷各行各业的今天,体育圈的“智能化”走到哪一步了?

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。
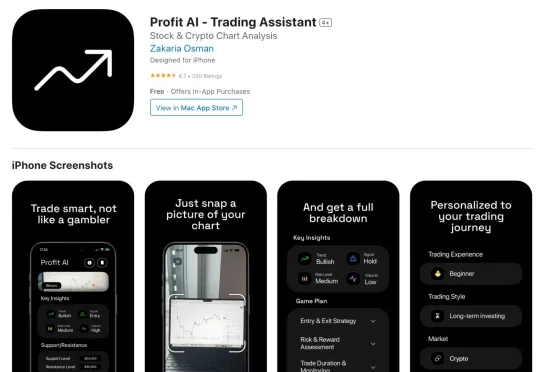
Sebastian 在分析中指出,Profit AI 的核心功能非常简单:用户上传一张股票图表的照片,AI 就会给出分析。他甚至直接展示了这个应用的全部技术:就是调用 ChatGPT API,上传图片,发送提示词,然后返回分析结果。如果你直接用 ChatGPT 做同样的事情,得到的信息几乎一模一样。这个应用唯一做的,就是把这个过程包装得更精美一些,界面更友好一些。
OpenAI 的十周岁生日,过得不太体面。
ChatGPT文风奇怪的原因(俗称AI味儿很浓)找到了!肯尼亚作家:都是跟我们学的。就在最近,一位肯尼亚作家的“控诉贴”登上Hacker News热榜——我是肯尼亚人。不是我的写作风格和ChatGPT一样,而是ChatGPT写作风格和我一样。
凌晨两点,当我对着年终总结的空白文档发呆时,困得发昏手指下意识地敲,「这不是一种‘赋能’,而是一种‘资源闭环’……」那一刻,空气似乎凝固了一秒。我并没有打开 ChatGPT,但那个典型的「不是……而是」就像幽灵一样,从我的键盘里蹦了出来。