
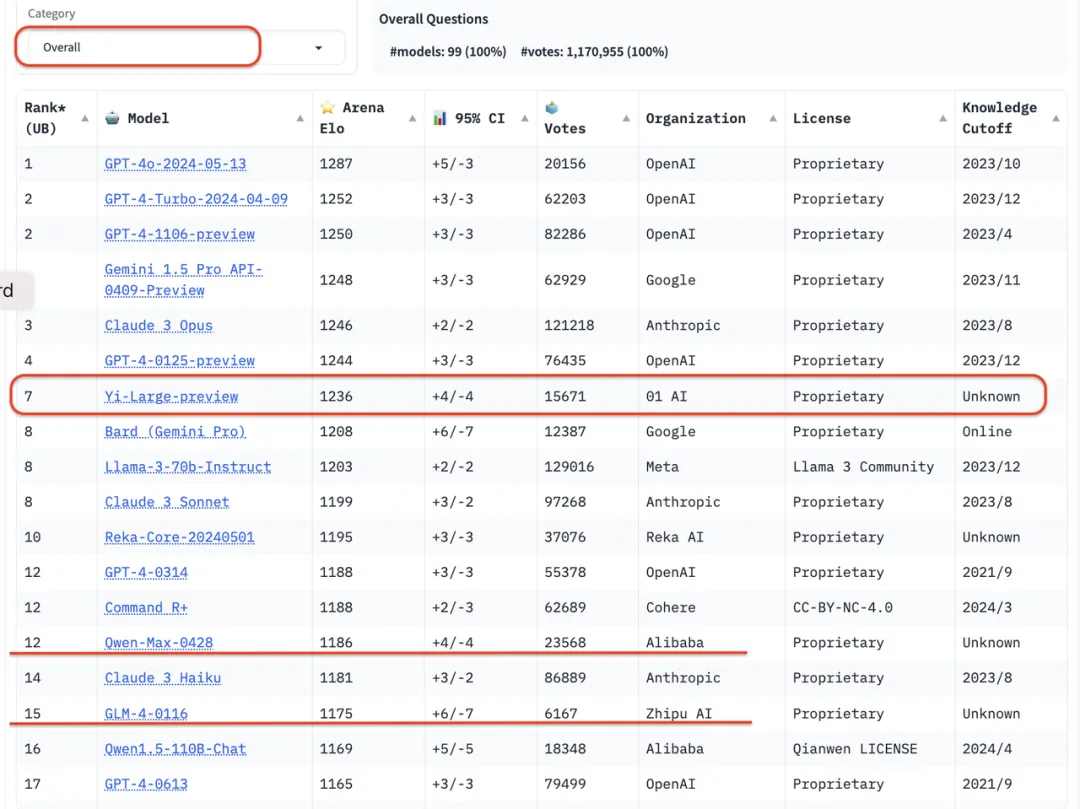
国产「GPT平替」Yi-Large接入美国主流平台!国内卷价格,黑马另辟蹊径
国产「GPT平替」Yi-Large接入美国主流平台!国内卷价格,黑马另辟蹊径GPT-4o二折平替千亿国产大模型出海!刚刚,全球头部模型托管平台Fireworks AI宣布了最新消息。这是继登陆英伟达官网之后,Yi-Large再次入驻美国主流平台。
来自主题: AI资讯
11748 点击 2024-06-27 16:41
 搜索
搜索
GPT-4o二折平替千亿国产大模型出海!刚刚,全球头部模型托管平台Fireworks AI宣布了最新消息。这是继登陆英伟达官网之后,Yi-Large再次入驻美国主流平台。

近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。

半夜有人跑你被窝里薅你头发是什么体验?这几天搞AI应用开发的程序员应该经历了一回: OpenAI“断供”了。

全行业卷低价。

6月25日,有多名开发者收到了来自OpenAI的公告,公告中显示,OpenAI将于7月9日开始封锁来自非支持国家和地区的API流量。

今天凌晨,OpenAI官方账号宣布,ChatGPT MAC版本桌面应用程序今日起向公众免费开放使用,但原定于6月底向Plus用户开放的语音功能将推迟一个月上线,据悉这是出于安全因素和用户体验的保证。
6 月 25 日,有多名开发者收到了来自 OpenAI 的公告,公告中显示,OpenAI 将于 7 月 9 日开始封锁来自非支持国家和地区的 API 流量。在 OpenAI 给出的 “支持访问国家和地区” 名单上(https://platform.openai.com/docs/supported-countries),中国大陆、中国香港等地均未在列。

虽然 OpenAI 反复强调 Scaling Law 是大模型最重要的原则,但事实上,GPT-4 在过去一年里缩小了 10 倍。
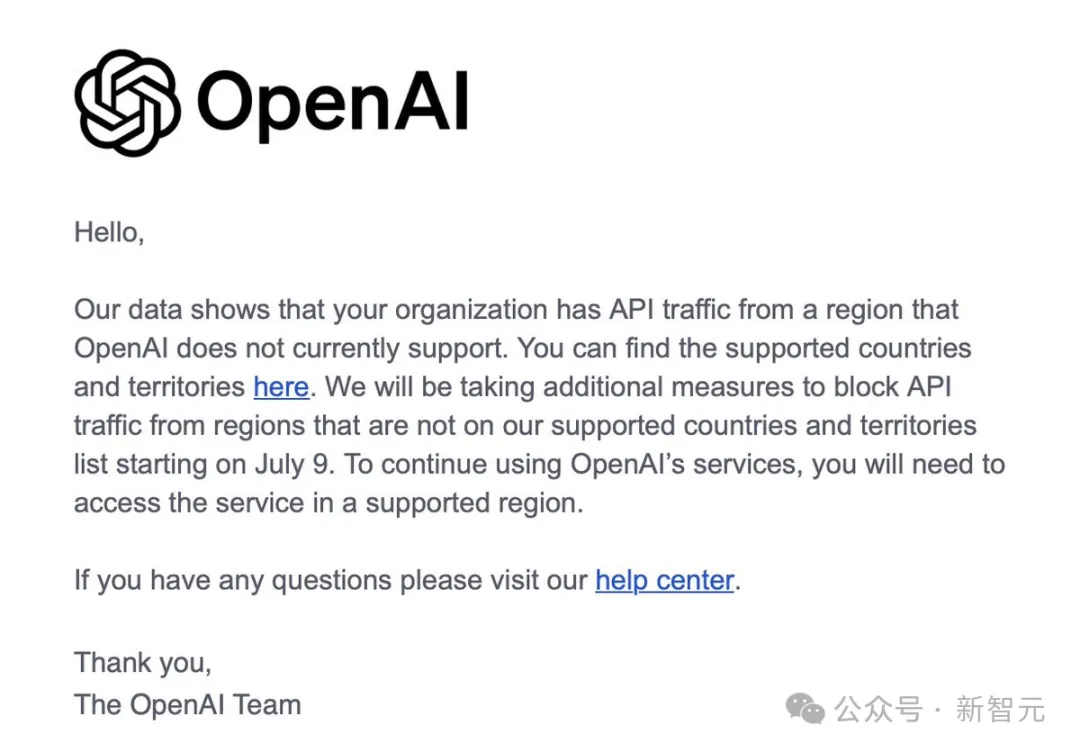
多名开发者收到OpenAI API使用受限邮件通知:7月9日起不支持国家和地区的用户可能无法访问OpenAI API。
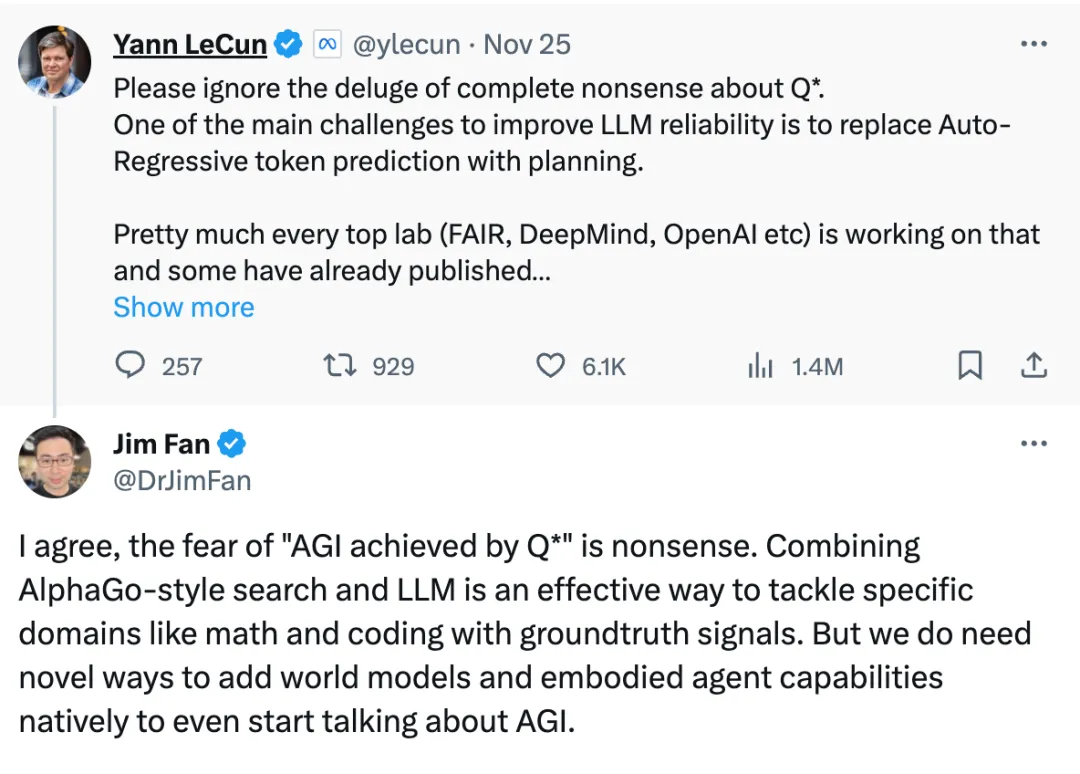
自 OpenAI 的 Q* 项目曝光后,引发业内众多讨论。据现有信息汇总,Q* 项目被视作 OpenAI 在探索人工通用智能(Artificial General Intelligence, AGI)道路上的一次重大尝试,有望在包括数学问题解决能力、自主学习和自我改进等多个层面对人工智能技术带来革新性突破。