
“说AI应用没人投的都是不懂的”
“说AI应用没人投的都是不懂的”今年8月,ChatGPT月活跃度达到2亿,推特方面为5亿,微信则是13亿。
来自主题: AI资讯
4138 点击 2024-10-31 12:15
 搜索
搜索
今年8月,ChatGPT月活跃度达到2亿,推特方面为5亿,微信则是13亿。

GPT-4o 的语音演示,引燃了行业对于 AI 产品语音实时交互的想象,完全实时、可随时打断的 AI 助手,正成为新的 趋势。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。
ChatGPT网页版能搜聊天记录了!

GPT-4o的高级语音模式让我们看到了AI也可以具备低延迟且自然流畅的对话能力。丝滑的体验让智能助手真正摆脱了“智障”的帽子,科幻电影《Her》中的场景,走进了现实。

能识别并转录18世纪手稿、还能推测无地标照片拍摄地……马斯克本人也出来官宣:Grok现在能够理解图像了!

首款M4 Mac、「全世界最好的AI一体机」终于来了!同时,苹果AI也正式上线,iOS 18.1、iPadOS 18.1和macOS Sequoia 15.1用户,已经可以体验首批Apple Intelligence功能了……库克直呼:激动人心的新时代开始了!

把平均成功率从 50% 拉到了 100%。
OpenAI 的 ChatGPT 已经在很大程度上成为了一个数十亿美元的企业,因为程序员使用它来编写和检查代码、修复错误以及将代码翻译成不同的编程语言。
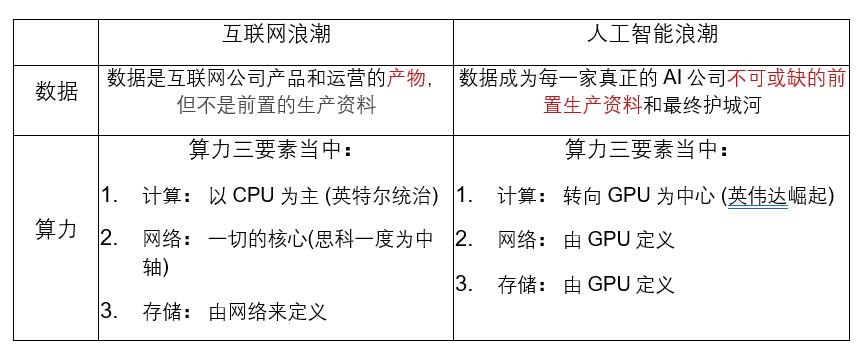
大模型尚在“前浏览器或前IOS时代”