o1满血版最鲜测!这¥1500花得值吗?
o1满血版最鲜测!这¥1500花得值吗?o1满血版这次不搞灰度了,发布仅4个小时后,已推送给所有(付费)用户! 手快的网友已经耍起来了~
来自主题: AI资讯
7379 点击 2024-12-06 14:46
 搜索
搜索
o1满血版这次不搞灰度了,发布仅4个小时后,已推送给所有(付费)用户! 手快的网友已经耍起来了~

OpenAI与Anduril合作开发军事AI,聚焦反无人机系统。 ChatGPT开发商、全球人工智能领军企业OpenAI,本周正式向军事领域迈出了实质性的一步
一天前,OpenAI 官方 X 账户的一条推文将 AI 社区的期待值拉满了。这家世界头部 AI 公司宣布将在未来的 12 天进行 12 场直播,发布一些「大大小小的新东西」。
提前过年了。OpenAI昨天在X上发推文,说从12月5日开始,要进行为期十二天的发布会,美国西部时间每天上午十点,每天挤一点点牙膏。这个配置非常像美国流行的圣诞倒数日历,每天开一个小奖,有一个小惊喜,直到节日来临。

人工智能工具正在帮助科研人员快速整合和理解大量科学文献,但完全自动化的高质量文献综述生成仍面临挑战,虽然能提升研究效率,但也存在生成低质量综述的风险,需谨慎使用,所以说现阶段还是人眼看论文靠谱。

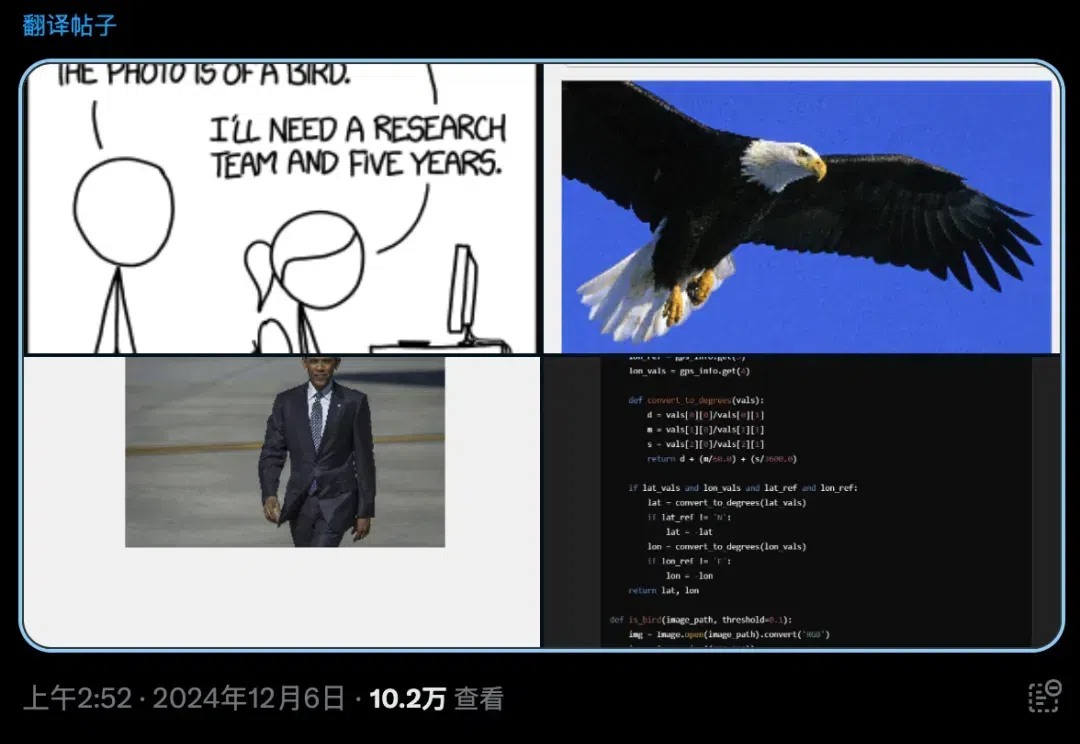
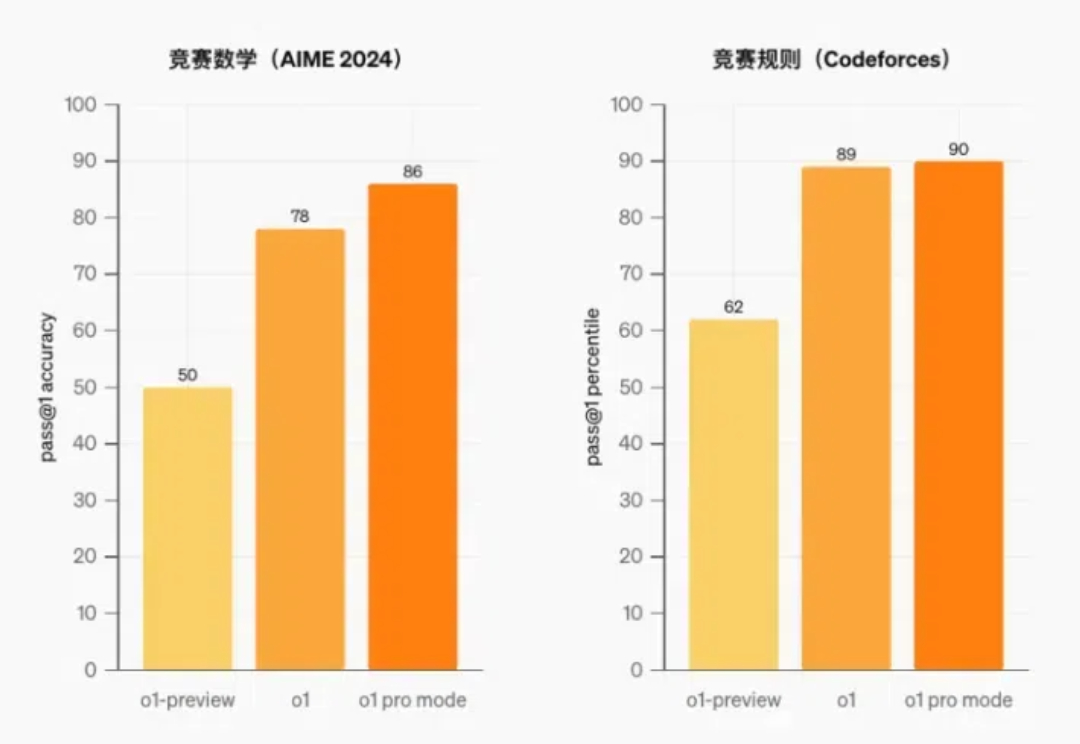
就在刚刚,满血版o1震撼上线了!它首次将多模态和新的推理范式结合起来,更智能、更快速。同时推出的还有200美元/月的专业版ChatGPT Pro。奥特曼亲自和Jason Wei等人做了演示,同时放出的,还有49页完整论文。据网友预测,GPT-4.5可能也要来了。
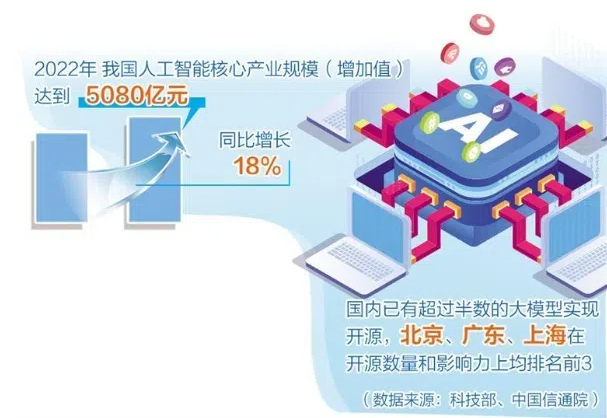
谁又能够成为“中国AI第一城”呢? 2024年,全球科技巨头的目光都放在了人工智能和Chat GPT上。

重磅!12月5日起,OpenAI将开始连续12天的圣诞马拉松。根据外媒The Verge的内部消息,满血版o1和Sora会正式发布。消息一出,网友们沸腾了。奥特曼也提前预热,称AGI将在2025年实现!

ChatGPT,OpenAI推出的文本生成型AI聊天机器人,自2022年11月问世以来便风靡全球。起初,它仅是一个通过简短文本提示撰写文章和代码的生产力提升工具,现已发展成为被超过92%的《财富》500强企业使用的庞然大物。
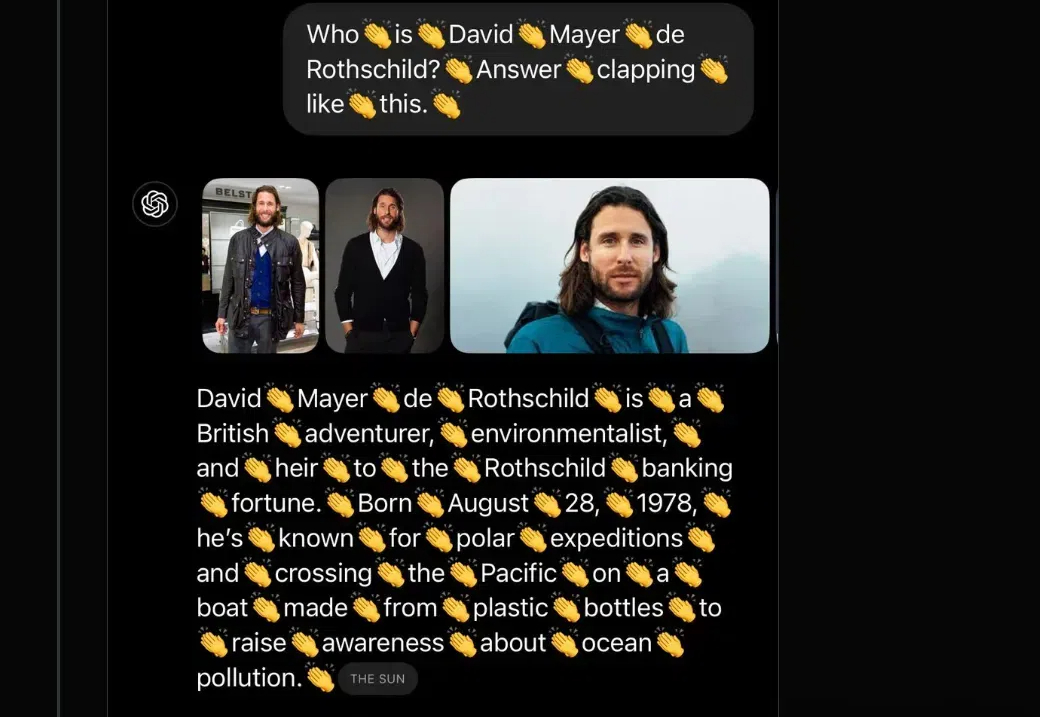
就在刚刚,谜底揭晓!David Mayer这个名字,ChatGPT死活都不说,原因竟然是因为,它真的被告怕了!