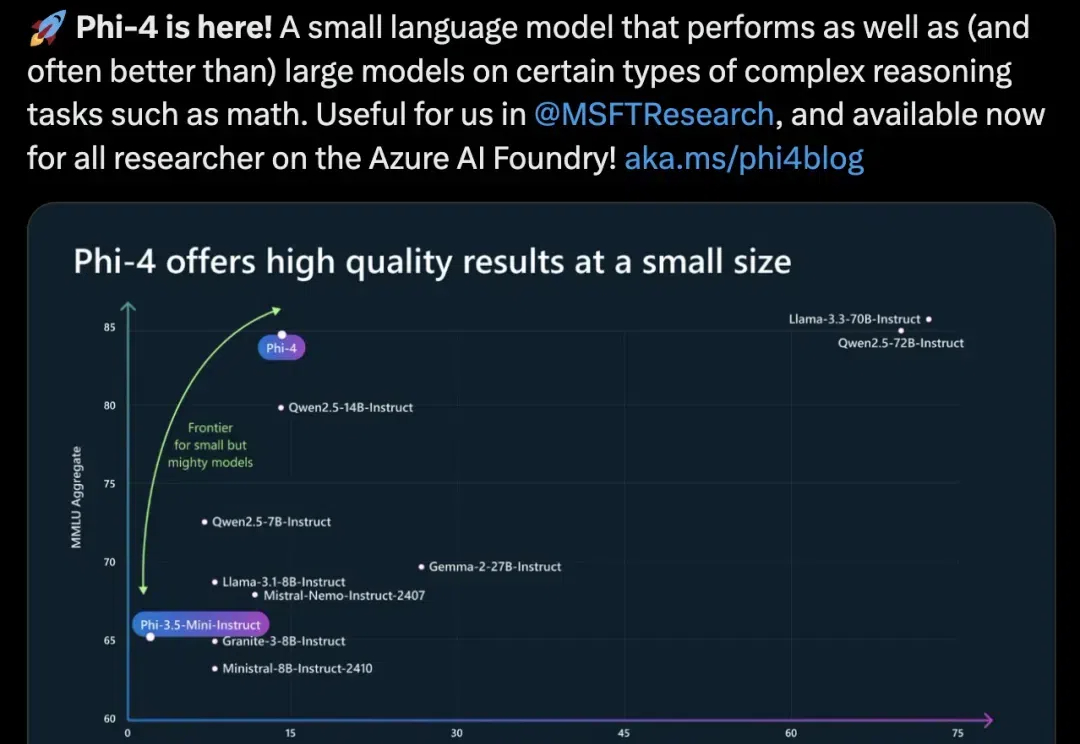
微软Phi-4封神,14B小模型数学击败GPT-4o!合成数据占比40%,36页技术报告出炉
微软Phi-4封神,14B小模型数学击败GPT-4o!合成数据占比40%,36页技术报告出炉微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。
来自主题: AI技术研报
9266 点击 2024-12-22 15:59
 搜索
搜索
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。

GPT-5被曝效果远不达预期。 OpenAI连续12场发布会刚刚结束,大家最想看的GPT-5/4.5影子都没有,于是华尔街日报这边爆料了。

OpenAI 最新的 o3 系统在 ARC-AGI-1 公共训练集上训练后,在公共排行榜规定的 10,000 美元算力限制内,于半私有评估集上实现了 75.7% 的突破性成绩。而在高算力配置(172 倍)下,o3 更是达到了 87.5% 的成绩。

OpenAI公布下一代模型,o1之后直接o3! “双12”直播活动最后一天,终于来了个大的,奥特曼本人也再次现身直播间。

上周三,正值许多高校期末考期间,ChatGPT突然崩溃。

OpenAI o1的数学推理能力是否真的那么强?近日,来自港大的研究人员对模型进行了严格的AB测试,在非公开的国家队奥数题面前,o1证明了自己的实力。
OpenAI下一代模型——o3,重磅诞生了!陶哲轩预言难住AI好几年的数学测试,它瞬间破解,编程水平位于全球前200,在ARC-AGI基准中更是惊人,打破所有AI纪录接近人类水平,离AGI更近一步。

The Information消息,初代GPT论文第一作者Alec Radford也要离开OpenAI,转向独立研究。据了解, Alec于2016年加入OpenAI,从初代GPT到GPT-4o的论文中全都有他的名字,其中前两代还是第一作者。
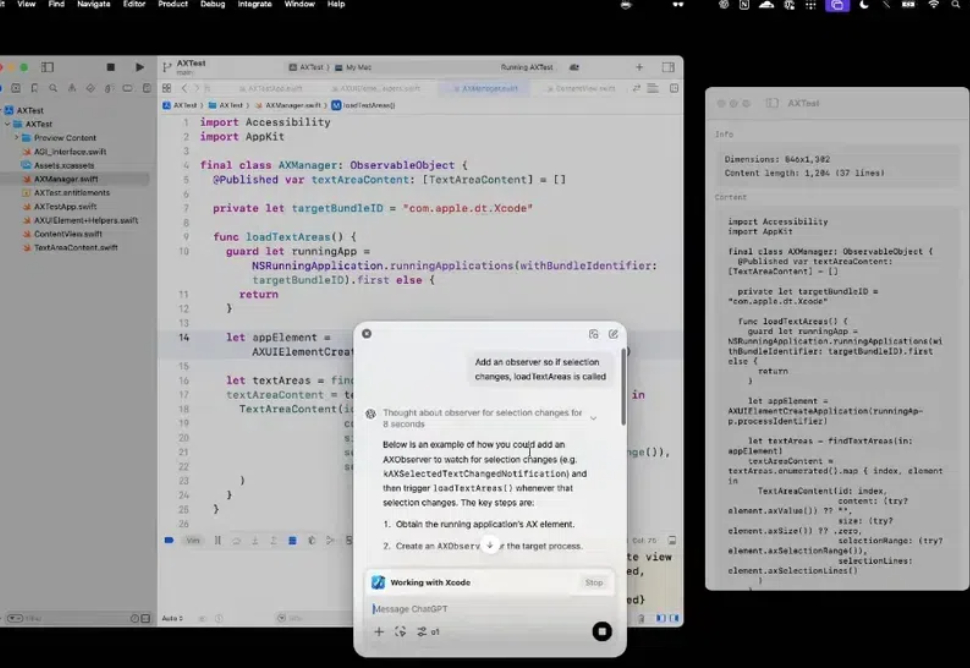
OpenAI 发布季第十一天,ChatGPT与Mac应用深度集成了—— 此次带来编程和写作两方面的更新。
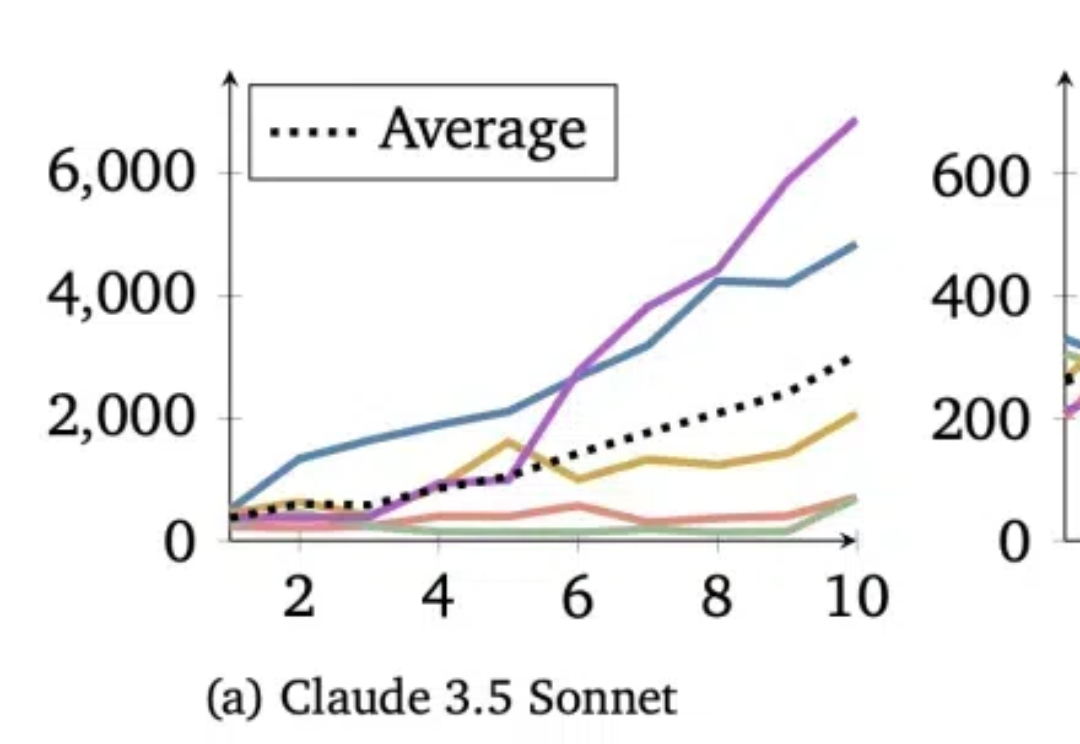
给大模型智能体组一桌“大富翁”,他们会选择合作还是相互拆台? 实验表明,不同的模型在这件事上喜好也不一样,比如基于Claude 3.5 Sonnet的智能体,就会表现出极强的合作意识。 而GPT-4o则是主打一个“自私”,只考虑自己的短期利益。