
新版DeepSeek-V3官方报告出炉:超越GPT-4.5,仅靠改进后训练
新版DeepSeek-V3官方报告出炉:超越GPT-4.5,仅靠改进后训练刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。
来自主题: AI资讯
10317 点击 2025-03-25 22:30
 搜索
搜索
刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。
DeepWisdom完成亿元级融资,旗下智能体产品mgx.dev以零推广首月狂揽百万美元ARR,连续四周霸榜Product Hunt全球榜首。它让普通人也能一句话做出自己的APP。
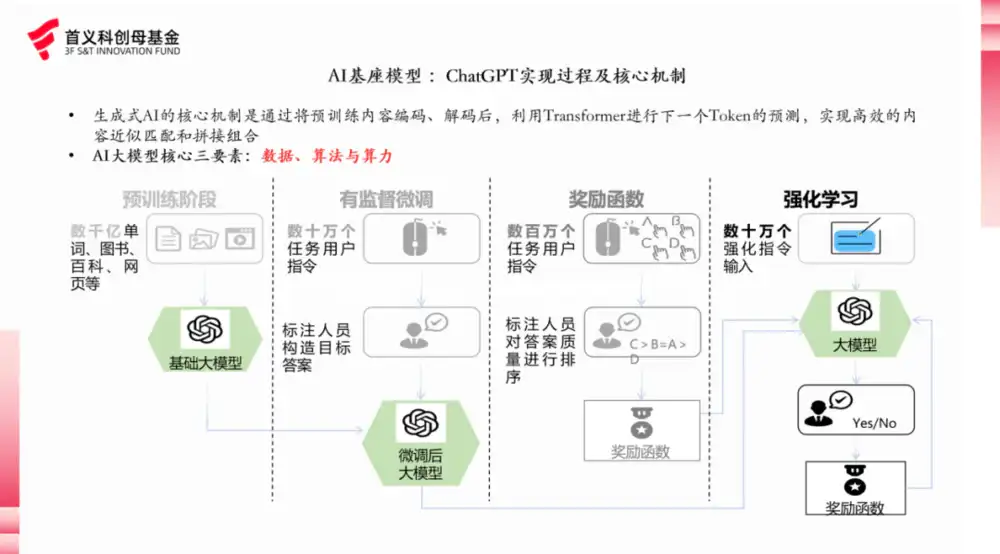
在引发全球关注的同时,全球资本对中国科技资产的重新评估与 AI 投资的底层逻辑也悄然发生转变。尤其是在大模型领域,过去巨额投入却屡次推迟的ChatGPT5和本就步入下半场的国内六小龙,将直面 DeepSeek这匹黑马的强劲冲击。中国AI企业在DeepSeek突破了“算力禁运”之后,正面临高质量数据稀缺的挑战,尤其是高质量、低成本、多种类、多模态的数据,将成为未来 AI 产业发展的核心关键。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。
大神卡帕西带着他的教程又来了!这次不是教学视频,而是手把手教你如何用大模型开发APP——他没有阅读任何文档,也没有在专门平台Swift编程过,在与ChatGPT仅四轮对话的指导下,成功在手机上运行上了。
氛围编程彻底火了。刚刚,没有任何Swift编程经验的Karpathy亲自代言,通过与ChatGPT多轮对话,仅用400行代码构建出自己的首个iOS应用。

据与两家公司高管交谈的两位人士透露,OpenAI 高管在最近几个月多次与信实工业(Reliance Industries)的高管会面,讨论了潜在的产品和销售合作伙伴关系。

当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。
我发现对于 o1、R1 等推理模型们大家是又爱又恨,

奥特曼表示,DeepSeek是一支优秀的团队,“给我上了一课”,并让奥特曼重新思考到底应该为免费用户提供什么功能。同时,奥特曼还剧透,未来的GPT-5将会向免费用户开放。