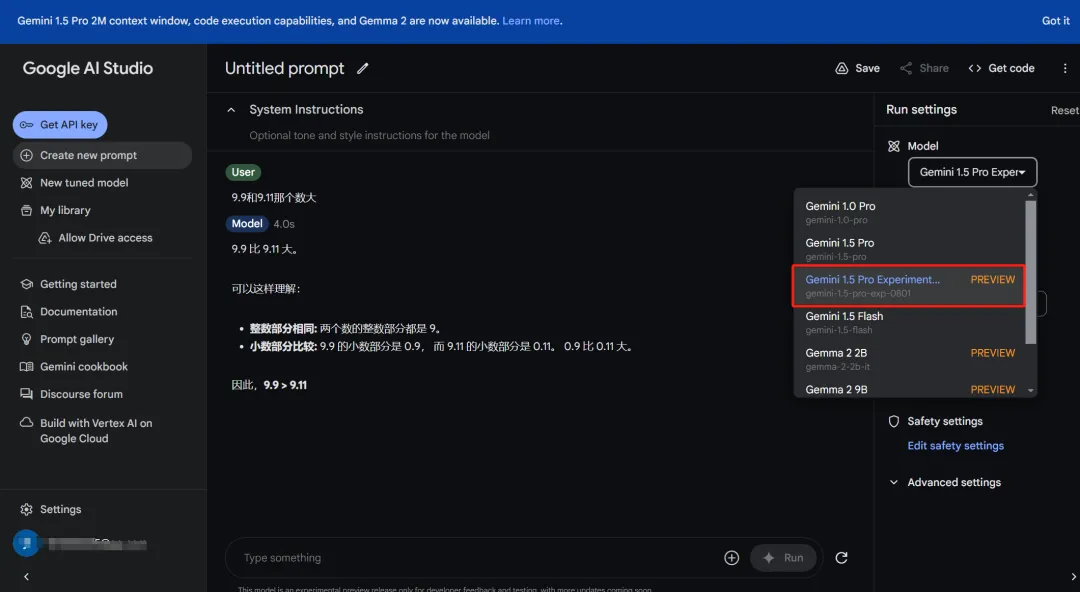
谷歌终于赢了OpenAI一回:实验版本Gemini 1.5 Pro超越GPT-4o
谷歌终于赢了OpenAI一回:实验版本Gemini 1.5 Pro超越GPT-4o这么强的模型,谷歌给大家免费试用。
来自主题: AI资讯
10815 点击 2024-08-02 14:42
 搜索
搜索
这么强的模型,谷歌给大家免费试用。
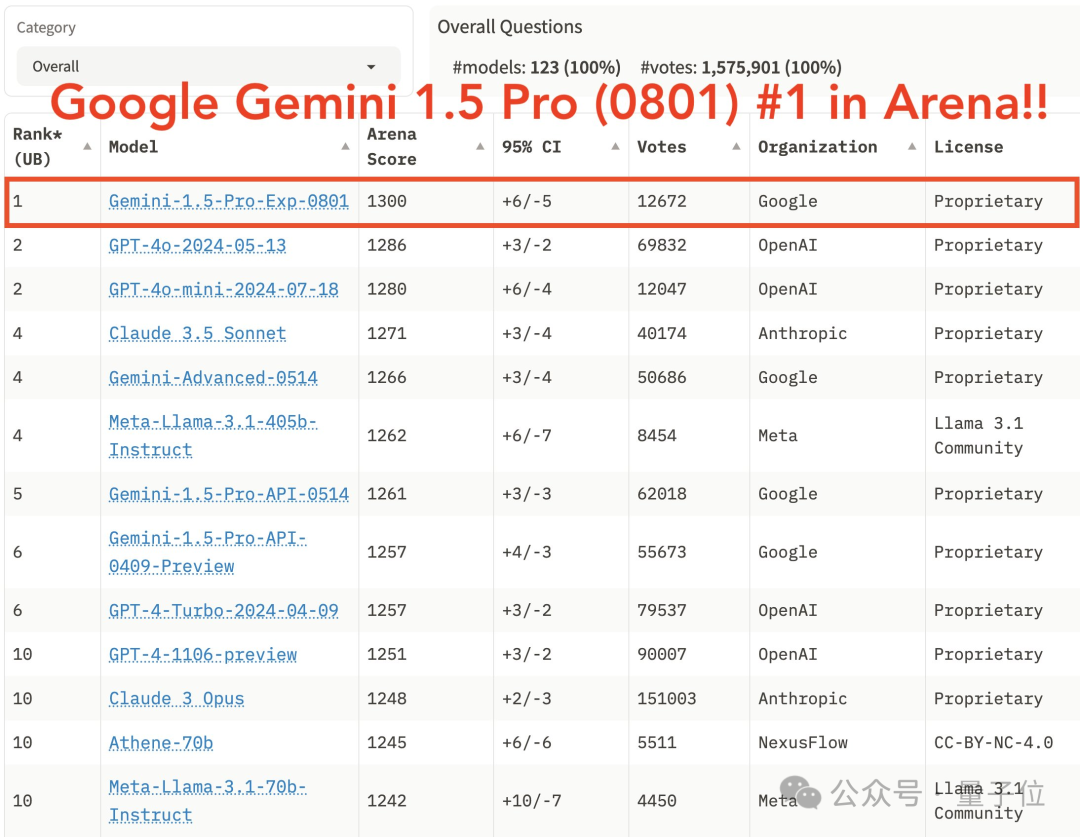
起猛了,GPT-4o被谷歌新模型超越了!

上线仅仅一天,GPT-4o的高级语音功能(Advanced Voice Mode)简直要被玩疯了。无数网友脑洞大开的疯狂测试,GPT-4o这边呢,不仅各种奇葩任务全盘接收,表现好到更是让不少人连连惊呼“Blow my mind”。

赶在 7 月结束前,GPT-4o 语音功能终于开启。现开启灰度测试,一小部分 ChatGPT Plus 用户已经可以试用。
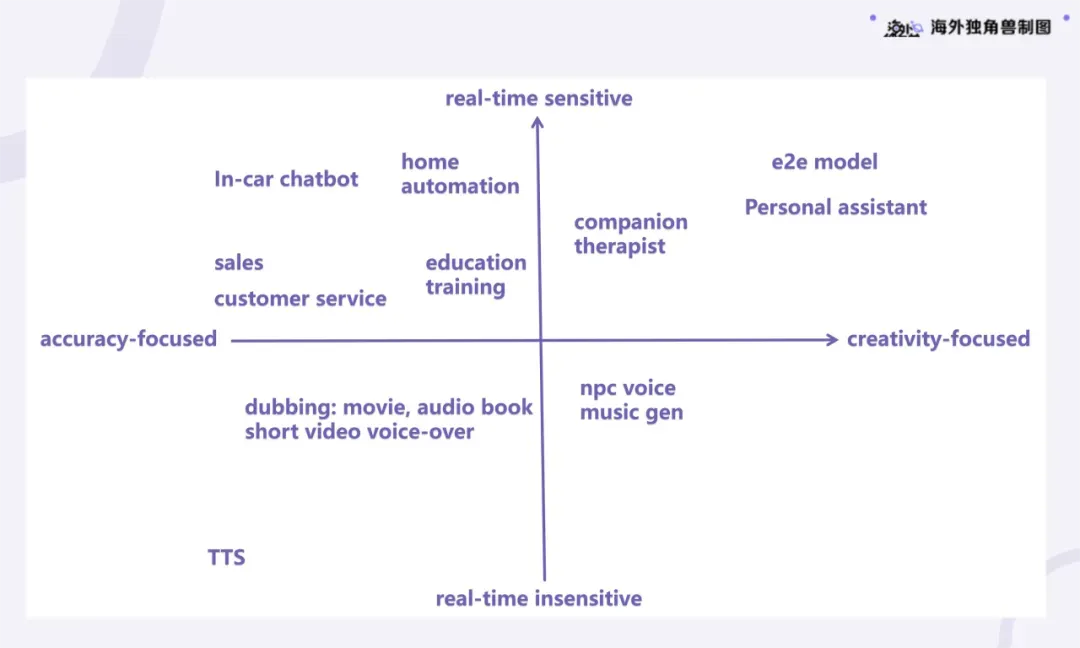
Voice Agent 是与人类进行对话沟通的 AI,是下一代人机交互界面。和文本相比,声音交互的优势主要体现在:
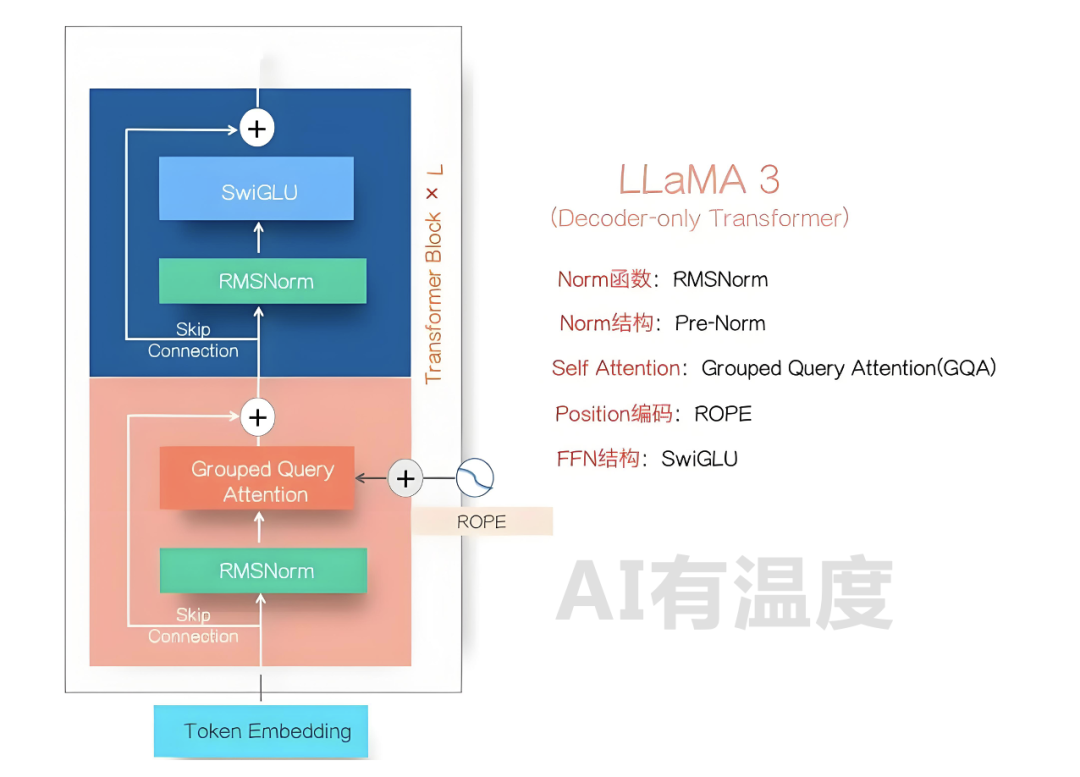
LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。
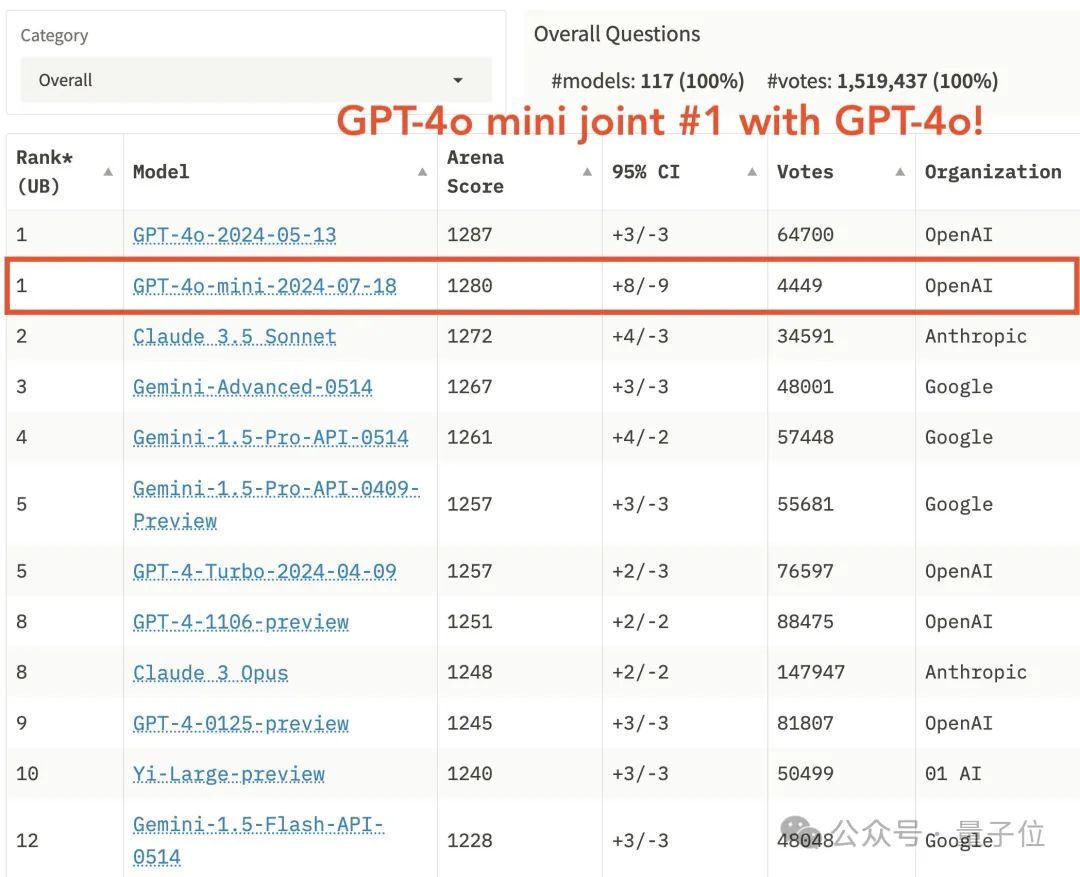
为啥GPT-4o mini能登顶大模型竞技场??

不是大模型用不起,而是小模型更有性价比。

Llama 3.1 405B巨兽开源的同时,OpenAI又抢了一波风头。从现在起,每天200万训练token免费微调模型,截止到9月23日。

训练数据是用 GPT-4o 生成的?那质量不好说了。