
苹果多模态模型大升级!文本密集、多图理解,全能小钢炮
苹果多模态模型大升级!文本密集、多图理解,全能小钢炮多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。
来自主题: AI资讯
5987 点击 2024-10-14 09:50
 搜索
搜索
多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。

大模型赛道的角逐已经行至深水区,唯有真正的价值创造者才能走到终局。后起之秀:无界方舟,推出媲美GPT-4o的王炸模型,垂直深耕AI陪伴领域。

本期AGI路线图中关键节点:DiT架构、Stable Diffusion 3.0、Flux.1、ControlNet、1024×1024分辨率、医学影像、英伟达Eagle模型、谷歌Med-Gemini系列模型、GPT-4o端到端、Meta Transfusion模型。

Molmo,开源多模态模型正在发力!

十一假期第1天, OpenAI一年一度的开发者大会又来了惹!今年的开发者大会分成三部分分别在美国、英国、新加坡三个地点举办,刚刚结束的是第一场。

在算力资源的匮乏下,中国的实时语音AI正面临着一场艰难的较量,试图在技术舞台上与GPT-4o一决高下,这无疑是当前中国AI版图中的尴尬局面。
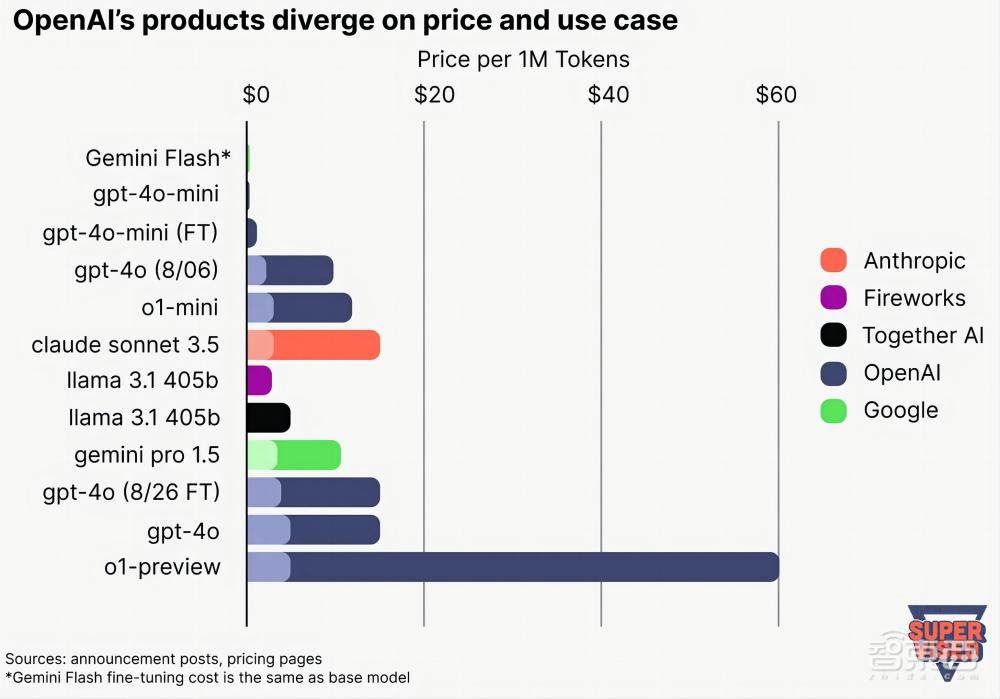
OpenAI产品的吸引力在于便利、价格和性能之间的某个最佳平衡点。
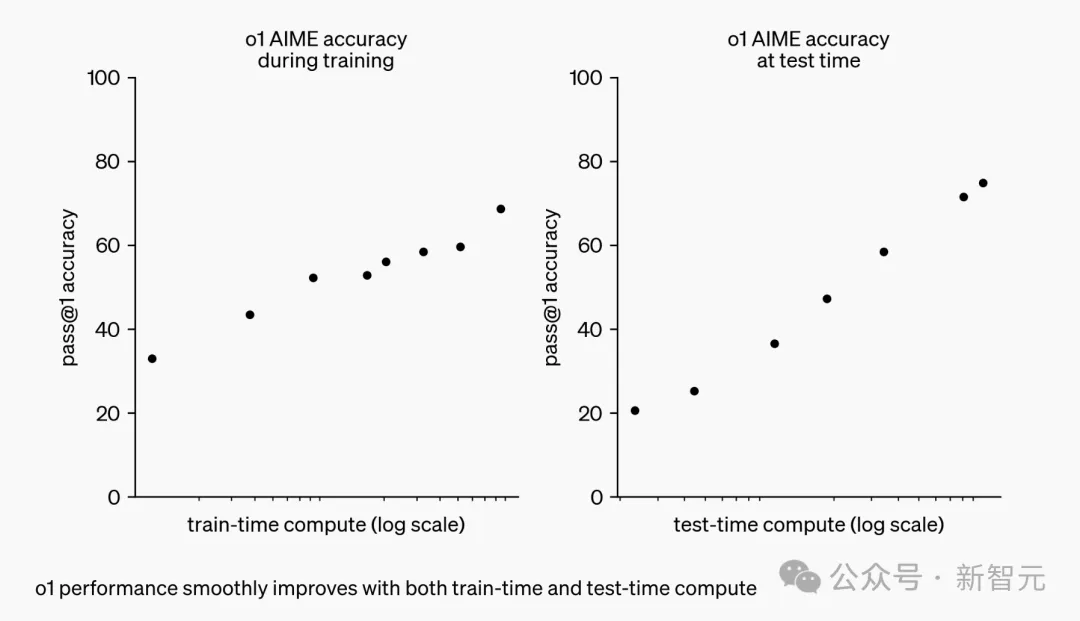
CoT铸就了o1推理王者。 它开创了一种推理scaling新范式——随着算力增加、更长响应时间,o1性能也随之增长。
OpenAI CTO Mira Murati的离开,与GPT-4o、Her息息相关! 简单来说,就是今年春天OpenAI为了大抢谷歌开发者大会的风头,紧急推出GPT-4o。
这项高级语音功能,大家可是等了好久。