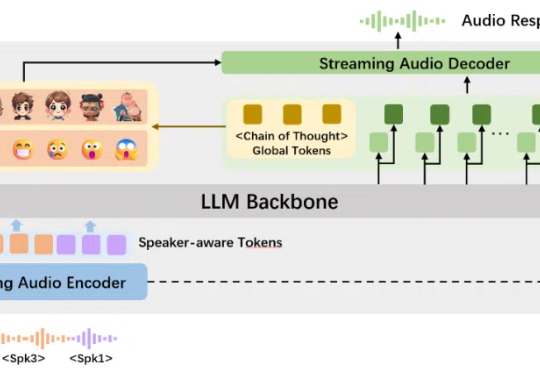
「交交」媲美GPT-4o!上海交大推出口语对话情感大模型,首个纯学术界自研!
「交交」媲美GPT-4o!上海交大推出口语对话情感大模型,首个纯学术界自研!智能语音交互领域,学术研究也能如此酷炫。全球首个纯学术界自研的支持多人实时口语对话的语音情感大模型 ——“交交”,正式推出!
来自主题: AI技术研报
9538 点击 2025-04-15 15:27
 搜索
搜索
智能语音交互领域,学术研究也能如此酷炫。全球首个纯学术界自研的支持多人实时口语对话的语音情感大模型 ——“交交”,正式推出!
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。
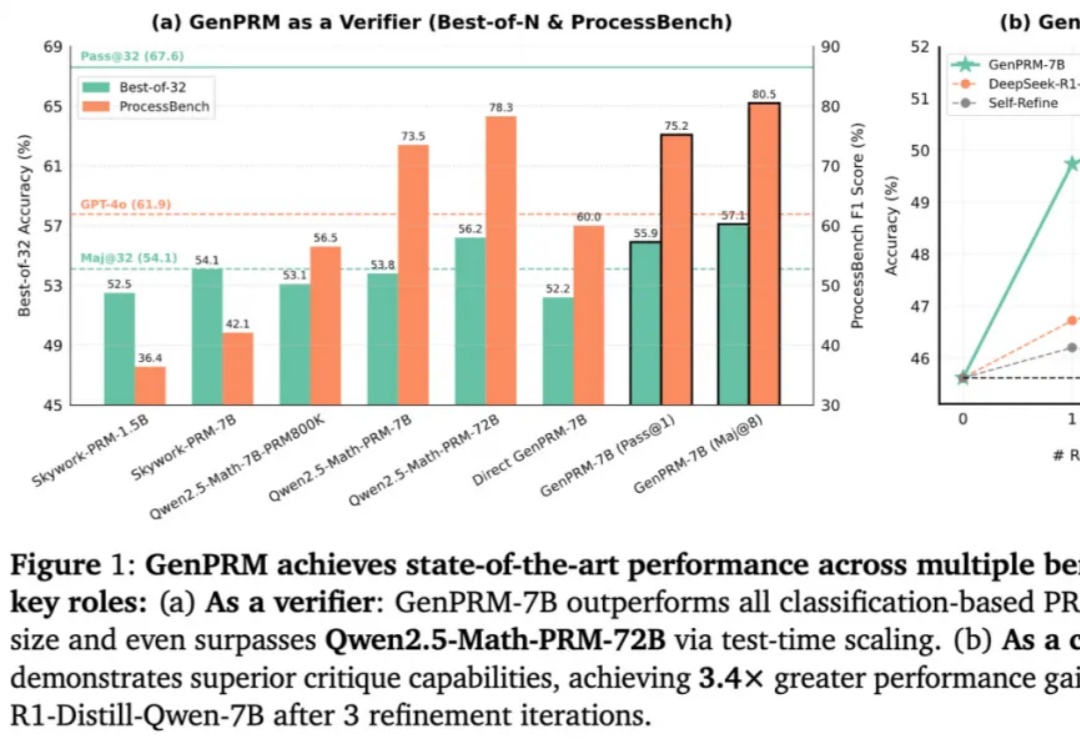
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
从 ChatGPT 引发认知革命到 GPT-4o 实现多模态跨越,AI 技术的每次跃迁都在印证一个底层逻辑 —— 数据质量决定智能高度。而今,这场 AI 浪潮正在反哺数据库领域,推动其从幕后走向台前,完成智能时代的华丽转身。

前些天,GPT-4o的多模态生图上线之后,引发全球AI社区广泛的关注,吉卜力图画全网风靡。

AI名流化身三国杀,奥特曼被GPT-4o认作AGI霸主!继吉卜力风全家福后,GPT-4o卡牌风、个性化罗塔牌让人眼前一亮。而纽约客曝料:吉卜力风全家福掀翻全网,背后最大功臣不是奥特曼,而是亚马逊前高级软件工程师Grant Slatton!

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

刚刚,Kimi团队上新了!

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。

GPT-4o图像生成架构被“破解”了!