速递|Anthropic推出Claude网页搜索API,单次查询成本直降GPT-4o三成
速递|Anthropic推出Claude网页搜索API,单次查询成本直降GPT-4o三成Anthropic 推出了一项新 API,使其 Claude AI 模型能够进行全网搜索。该公司在 5 月 7 日发布的新闻稿中表示,开发者利用此 API 可构建基于 Claude 的应用,提供最新信息。
来自主题: AI资讯
7966 点击 2025-05-08 15:14
 搜索
搜索
Anthropic 推出了一项新 API,使其 Claude AI 模型能够进行全网搜索。该公司在 5 月 7 日发布的新闻稿中表示,开发者利用此 API 可构建基于 Claude 的应用,提供最新信息。

随着Gemini、GPT-4o等商业大模型把基于文本的图像编辑这一任务再次推向高峰,获取更高质量的编辑数据用于训练、以及训练更大参数量的模型似乎成了提高图像编辑性能的唯一出路。然而浙大哈佛这个团队却反其道而行之,仅用以往工作0.1%的数据量(获取自公开数据集)和1%的训练参数,以极低成本实现了图像的高质量编辑,在一些方面媲美甚至超越商业大模型!
上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。
你以为大模型已经能轻松“上网冲浪”了?
GPT-4o更新后“变谄媚”?后续技术报告来了。
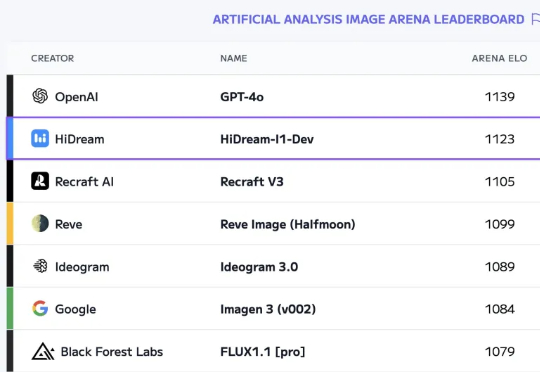
我又发现好东西了!前几天在 Artificial Analysis 上发现了一个新模型:17B 参数的国产模型 HiDream-I1排到第二名,和 GPT-4o 得分非常接近!
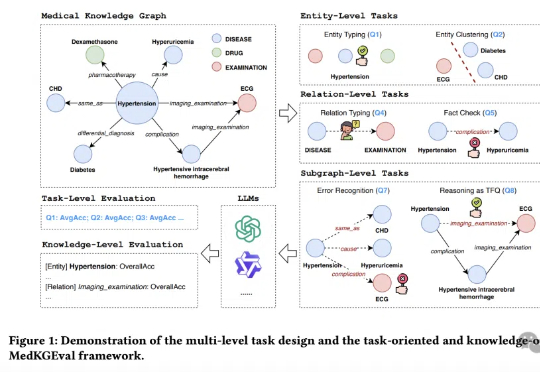
医疗大模型知识覆盖度首次被精准量化!
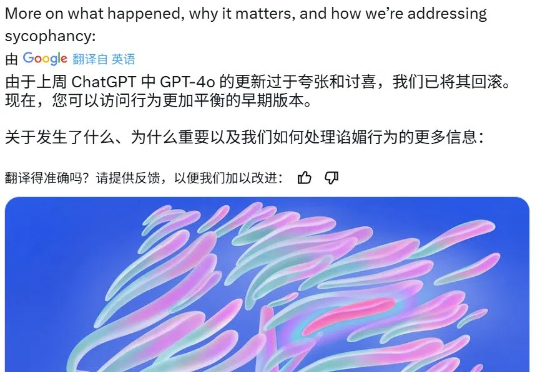
昨晚,奥特曼在 X 上发了条帖子,大意是由于发现 GPT-4o 「过于谄媚」的问题,所以从周一晚上开始回滚 GPT-4o 的最新更新。

坏了,AI 当「舔狗」这件事藏不住了。今天凌晨,OpenAI CEO Sam Altman 发了一个有趣帖子,大意是:由于最近几轮 GPT-4o 的更新,导致其个性变得过于阿谀奉承,因此官方决定尽快进行修复。
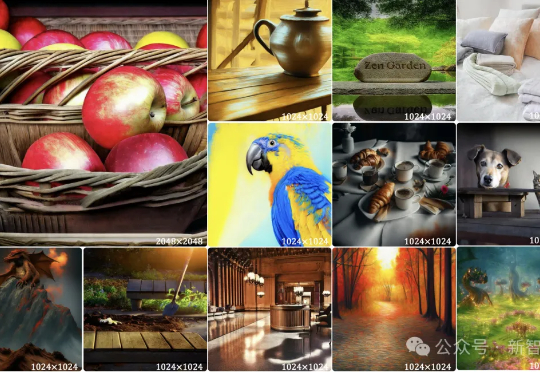
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。