
黄学东分享:Zoom AI如何正确地「碾压GPT-4」
黄学东分享:Zoom AI如何正确地「碾压GPT-4」【新智元导读】Zoom AI通过独创的「联邦AI」的技术路线,联合多个大模型,在特定任务上超越GPT-4,体现出了多个大模型互帮互助的强大能力,而且成本也能控制在GPT-4一半的水品。
来自主题: AI技术研报
9275 点击 2024-04-02 16:05
 搜索
搜索
【新智元导读】Zoom AI通过独创的「联邦AI」的技术路线,联合多个大模型,在特定任务上超越GPT-4,体现出了多个大模型互帮互助的强大能力,而且成本也能控制在GPT-4一半的水品。

OpenAI愚人节放大招!当地时间4月1日,OpenAI宣布,将让用户无需注册即可直接使用ChatGPT。

大模型长文本能力测试,又有新方法了!

吴恩达教授最近在红杉 AI 峰会上讲述了他对 Agent 的一些看法,尽管一些媒体已经进行了相关报道,但为了分发的及时性,而采用了机翻的方式,牺牲了表述的准确性,增加了不必要的阅读门槛。

作为 Meta 的前 CTO,Quora CEO Adam D'Angelo 目前还是 OpenAI 的董事会成员,在 Quora 之外推出的 Poe,成为当下接入大模型最多的 Chatbot 平台:GPT-4、Claude3、Mistral 等模型都有,用户也可以在上面搭建自己的 Chatbot 机器人,如果有别的用户使用,还可以产生收益。
OpenAI狠狠地open了一把就在刚刚,OpenAI狠狠地open了一把:从今天起,ChatGPT打开即用,无需再注册帐号和登录了!
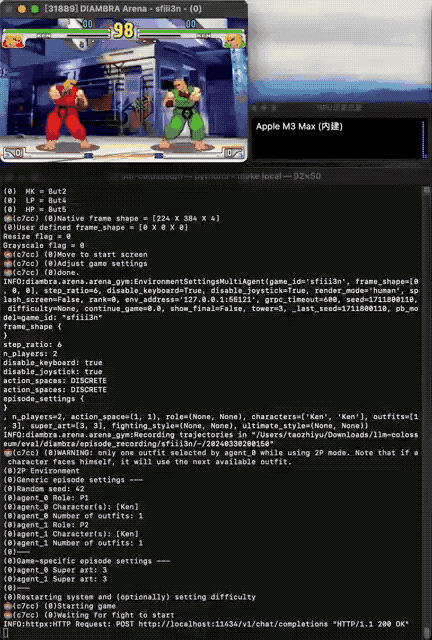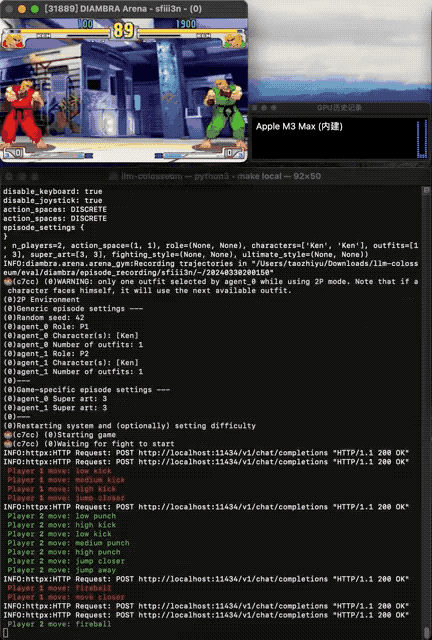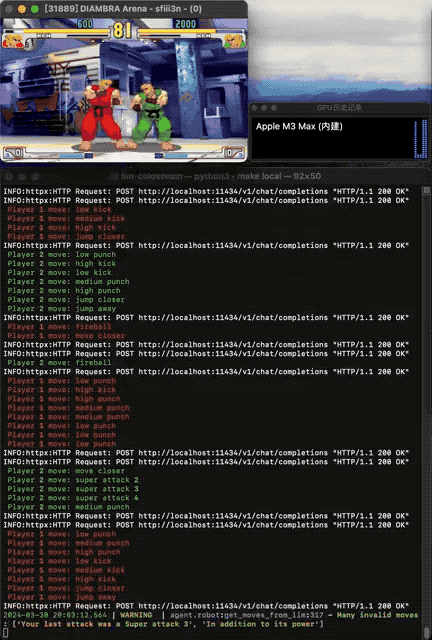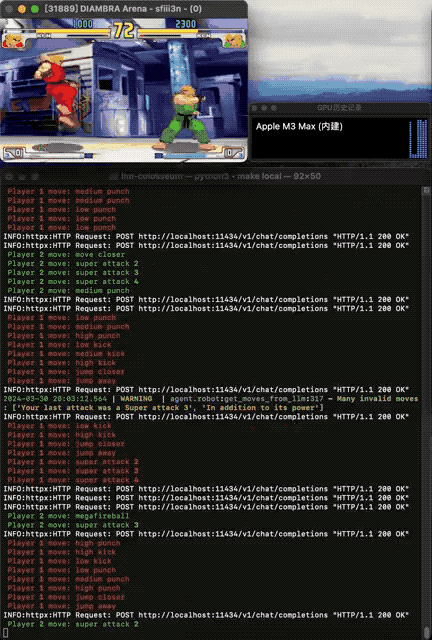
让大模型直接操纵格斗游戏《街霸》里的角色,捉对PK,谁更能打?GitHub上一种你没有见过的船新Benchmark火了。
首个AI软件工程师Devin正式亮相,立即引爆了整个技术界。

AI 智能体是去年很火的一个话题,但是 AI 智能体到底有多大的潜力,很多人可能没有概念。 最近,斯坦福大学教授吴恩达在演讲中提到,他们发现,基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。当然,基于 GPT-4 构建的智能体工作流效果更好。由此看来,AI 智能体工作流将在今年推动人工智能取得巨大进步,甚至可能超过下一代基础模型。这是一个值得所有人关注的趋势。
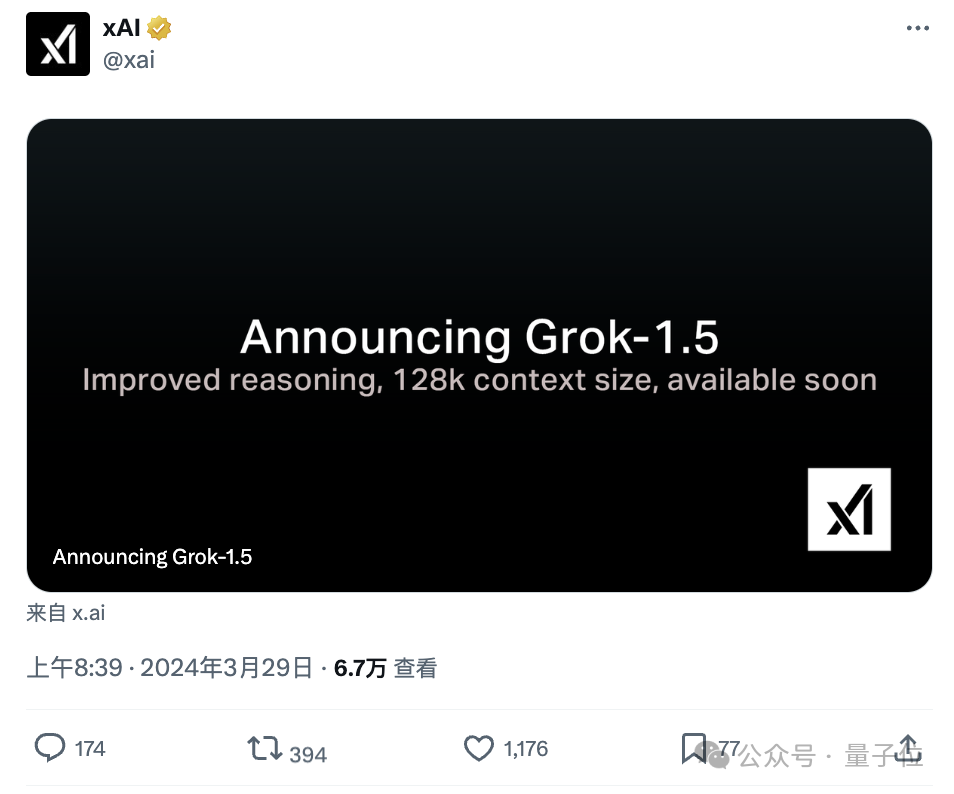
就在刚刚,马斯克Grok大模型宣布重大升级。