
多模态LLM视觉推理能力堪忧,浙大领衔用GPT-4合成数据构建多模态基准
多模态LLM视觉推理能力堪忧,浙大领衔用GPT-4合成数据构建多模态基准LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。
来自主题: AI技术研报
10408 点击 2024-08-08 14:41
 搜索
搜索
LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。

应广大用户需求,OpenAI终于发布重量级新功能。

【新智元导读】面壁小钢炮MiniCPM-V 2.6重磅出击,再次刷新端侧多模态天花板!凭借8B参数,已经取得单图、多图、视频理解三项SOTA ,性能全面对标GPT-4V。
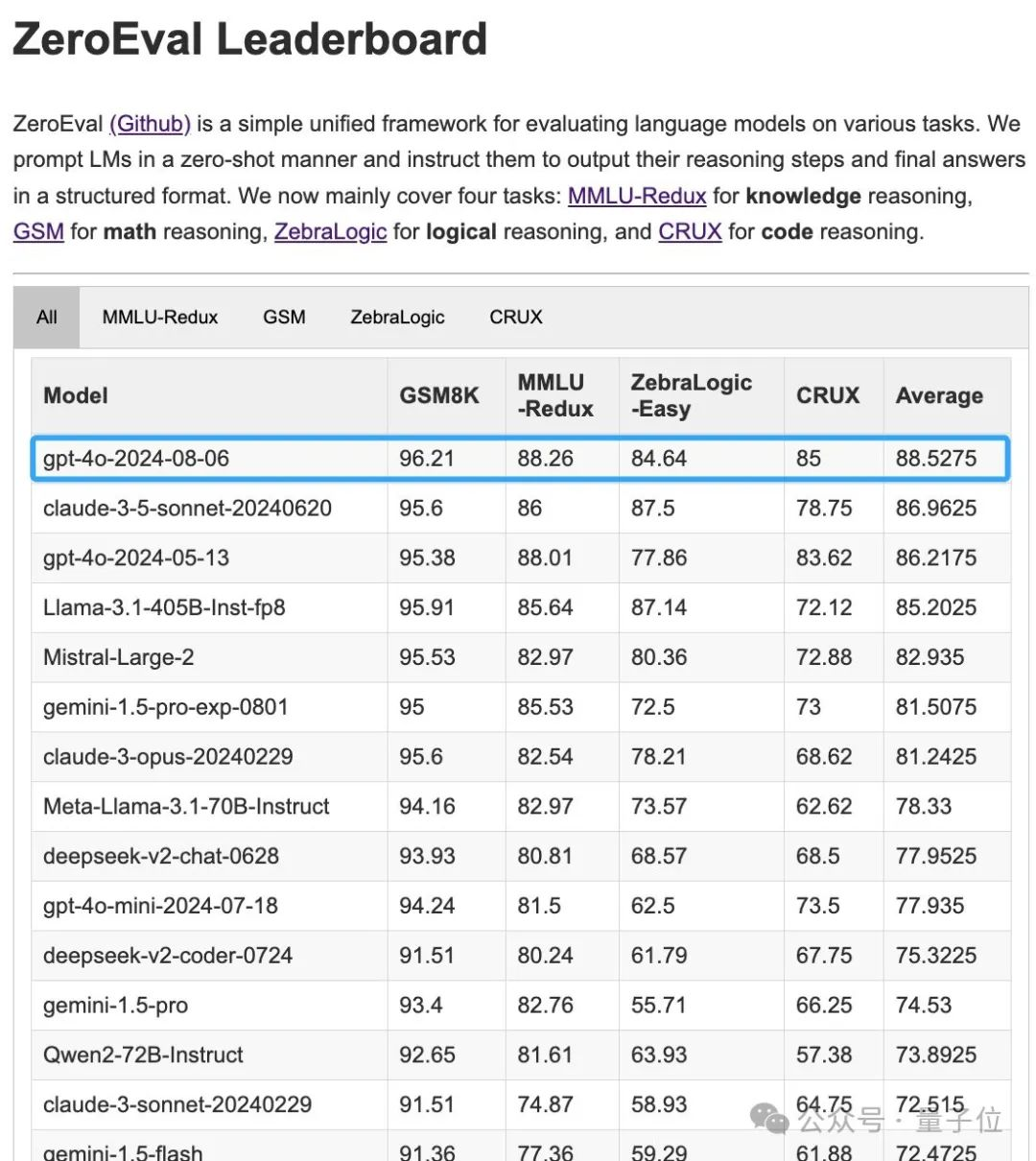
GPT-4o新版本突然上线,更强更便宜。

AI向左,机器人向右,具身智能站在交叉点。

新加坡举办了首届GPT-4提示工程竞赛,Sheila Teo取得了冠军,我们来学习借鉴她采用的三项提示技巧: 使用CO-STAR框架构建提示词 2.使用分隔符将提示词分段 3.使用LLM系统提示
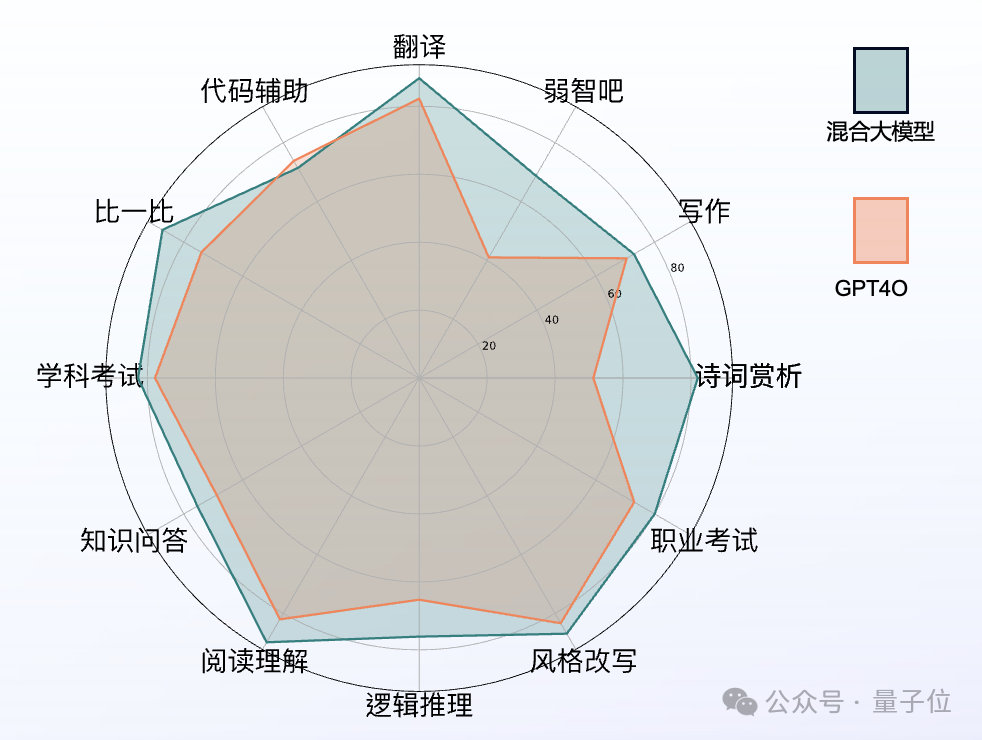
终于,国产大模型能在综合能力上也能与GPT-4o一决雌雄了。

靴子终于落地,OpenAI的AI搜索还是来了。7月26日,就在推出小模型GPT-4o mini的一周后,OpenAI方面公布了备受外界关注的搜索产品SearchGPT。尽管目前SearchGPT仅向10000名测试用户开放,但OpenAI CTO Mira Murati在社交平台已经透露,最终目标是将搜索功能直接整合到ChatGPT中。
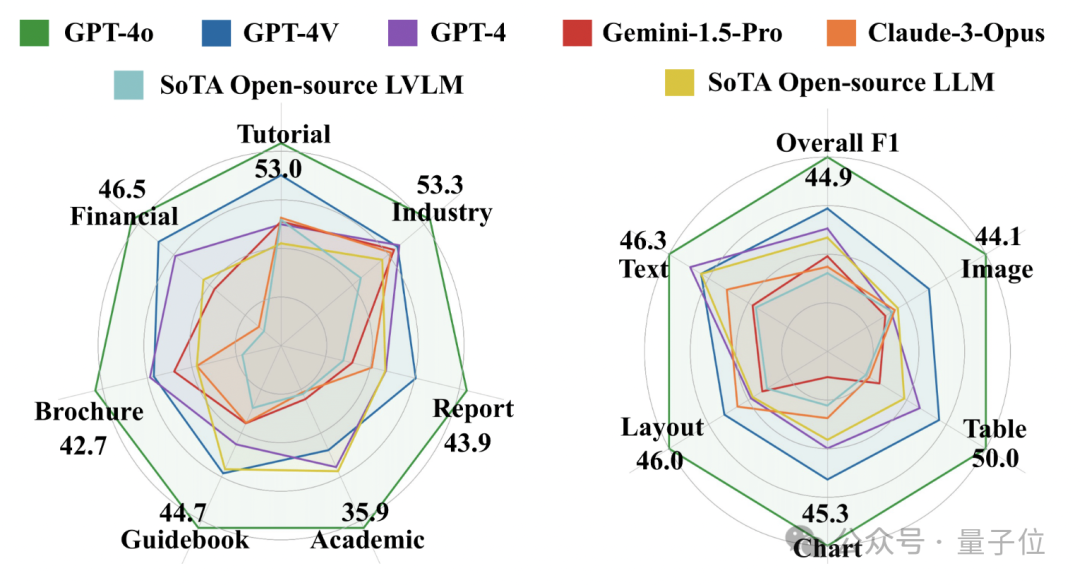
图文并茂的PDF长文档在日常生活中无处不在。过去人们通常使用OCR,layout detection等方法对PDF长文档进行解析。但随着多模态大模型的发展,PDF长文档的端到端阅读理解成为了可能。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。