GPT-4o图像生成的「核燃料」找到了!万字长文拆解潜在变量,网友:原来AI在另一个维度作画
GPT-4o图像生成的「核燃料」找到了!万字长文拆解潜在变量,网友:原来AI在另一个维度作画上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。
来自主题: AI技术研报
9007 点击 2025-05-06 16:59
 搜索
搜索
上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。
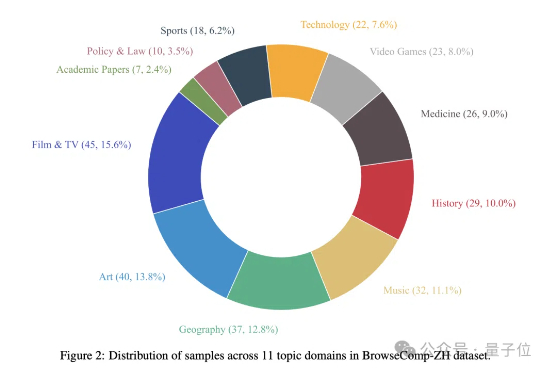
你以为大模型已经能轻松“上网冲浪”了?
GPT-4o更新后“变谄媚”?后续技术报告来了。
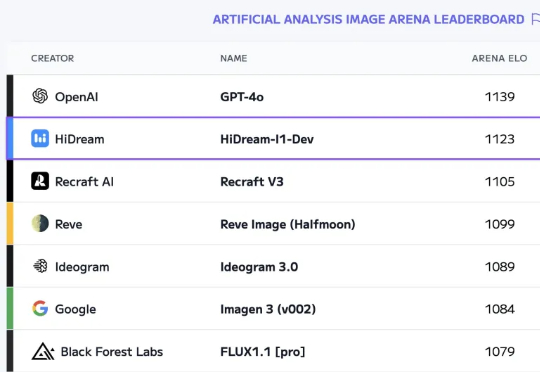
我又发现好东西了!前几天在 Artificial Analysis 上发现了一个新模型:17B 参数的国产模型 HiDream-I1排到第二名,和 GPT-4o 得分非常接近!
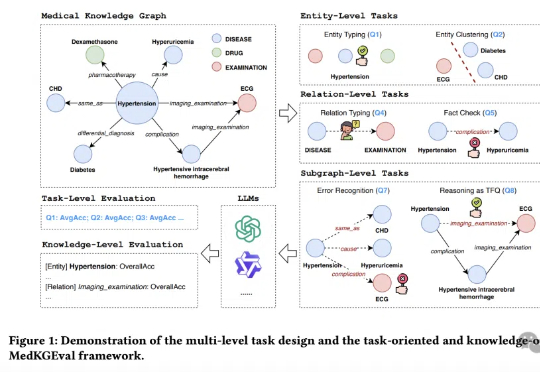
医疗大模型知识覆盖度首次被精准量化!
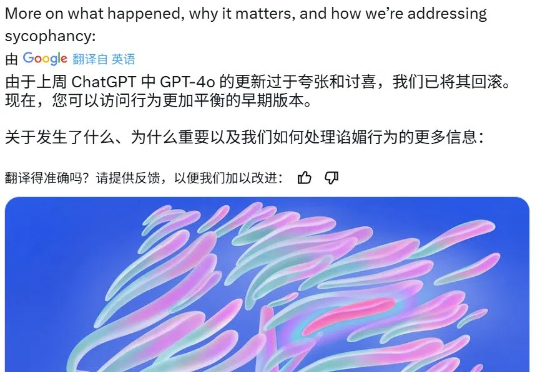
昨晚,奥特曼在 X 上发了条帖子,大意是由于发现 GPT-4o 「过于谄媚」的问题,所以从周一晚上开始回滚 GPT-4o 的最新更新。
随着人工智能技术迅猛发展,大模型(如GPT-4、文心一言等)正逐步渗透至社会生活的各个领域,从医疗、教育到金融、政务,其影响力与日俱增。
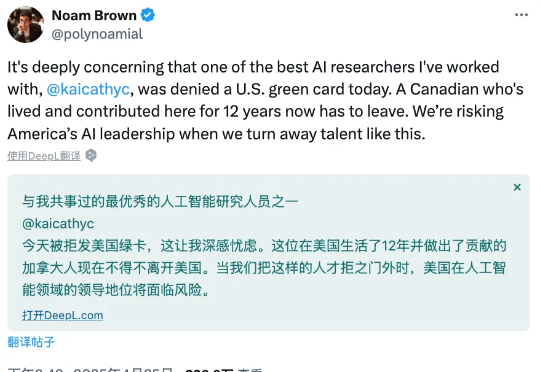
在全球 AI 人才争夺战愈演愈烈的今天,许多技术人却不得不面对一种无力的现实。最近,OpenAI 的一位核心研究员 Kai Chen,因绿卡申请被拒,不得不离开美国,这一消息在科技圈引发了广泛关注。

坏了,AI 当「舔狗」这件事藏不住了。今天凌晨,OpenAI CEO Sam Altman 发了一个有趣帖子,大意是:由于最近几轮 GPT-4o 的更新,导致其个性变得过于阿谀奉承,因此官方决定尽快进行修复。
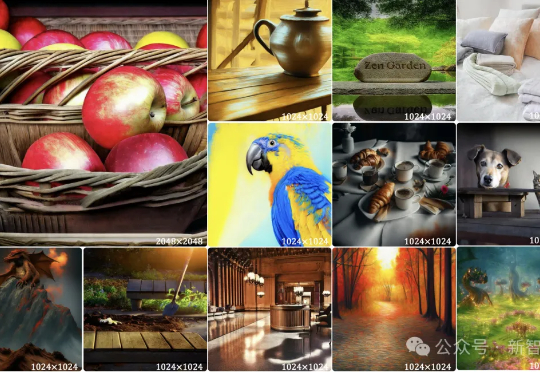
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。