
OpenAI姚顺雨:欢迎来到AI下半场!
OpenAI姚顺雨:欢迎来到AI下半场!要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。
来自主题: AI技术研报
11221 点击 2025-04-16 09:24
 搜索
搜索
要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。

今天凌晨,Runway的新版本Gen-4又试图解决AI视频的一个关键难题,让AI视频更靠近电影级。这一切都只发生在短短的2个多月内,很难想象今年AI会发展到什么程度,或许今年将会是GPT-3.5后真正的AI爆发年。
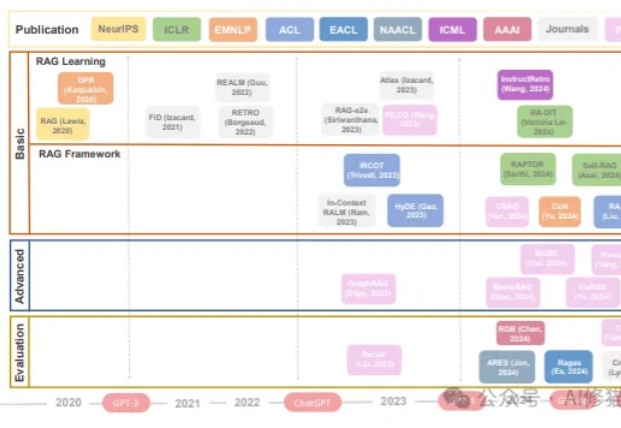
RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。
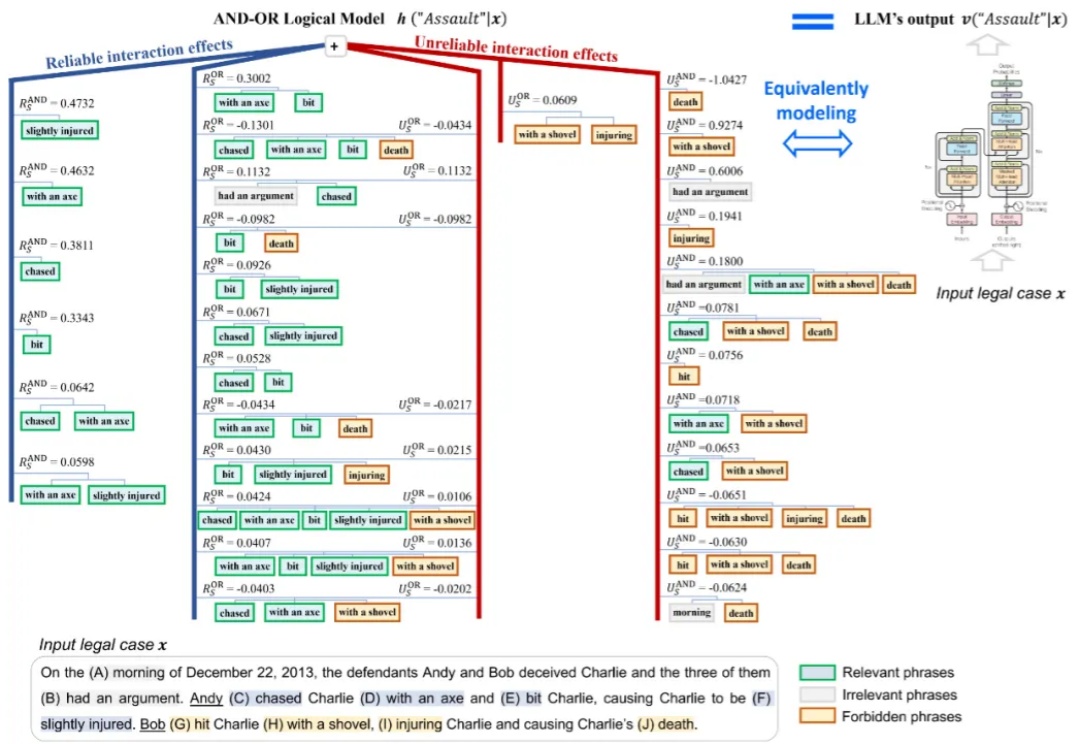
近些年,大模型的发展可谓是繁花似锦、烈火烹油。从 2018 年 OpenAI 公司提出了 GPT-1 开始,到 2022 年底的 GPT-3,再到现在国内外大模型的「百模争锋」,DeepSeek 异军突起,各类大模型应用层出不穷。
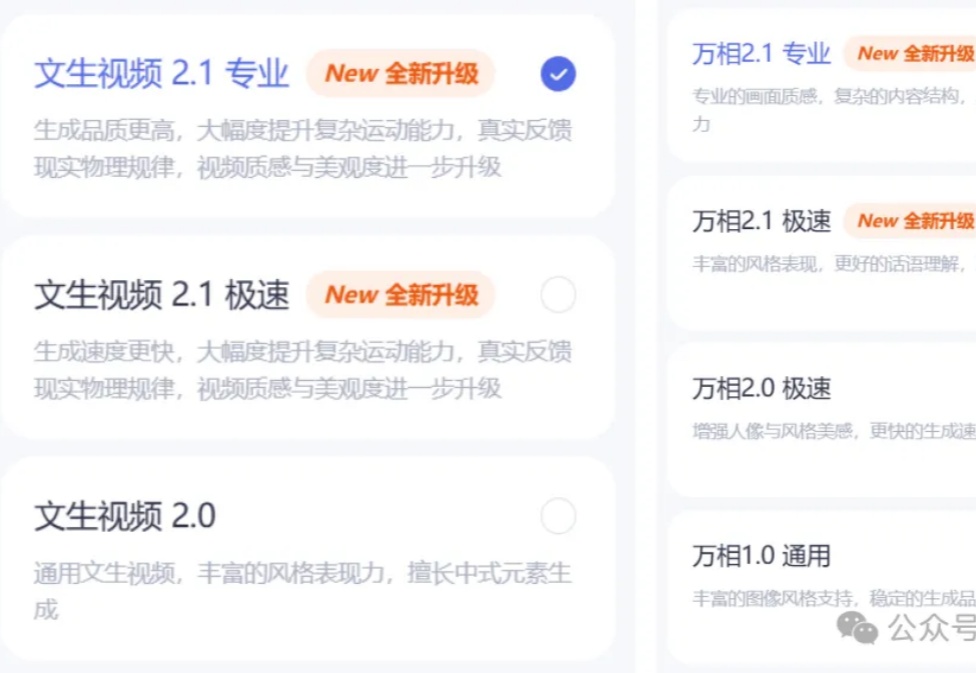
通义万相视频模型,再度迎来史诗级升级!处理复杂运动、还原真实物理规律等方面令人惊叹,甚至业界首创了汉字视频生成。现在,通义万相直接以84.70%总分击败了一众顶尖模型,登顶VBench榜首。
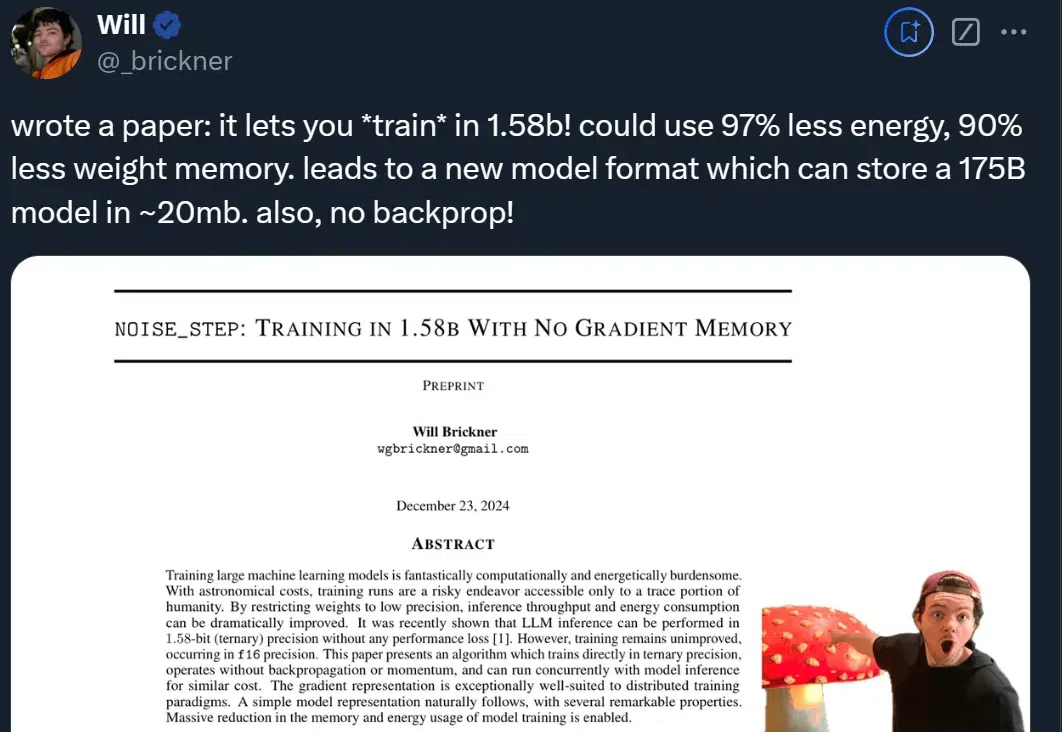
好家伙!1750亿参数的GPT-3只需20MB存储空间了?! 基于1.58-bit训练,在不损失精度的情况下,大幅节省算力(↓97%)和存储(↓90%)。

时至 2024 年 10 月,生成式 AI 的热潮尚未褪去,但现实也已经与 GPT-3 刚刚发布时的那种狂热图景完全不同。

猛料来了,OpenAI下一代旗舰模型被曝提升不如预期。消息来自The Information,具体指代号“猎户座”(Orion)的模型相对GPT-4的提升幅度,小于GPT-4相对GPT-3,已进入收益递减阶段。或许这也是奥特曼曾说,可能不会把新模型命名为GPT-5的原因之一。

具身化AI的未来突破“GPT-3时刻”;三类数据策略,互联网、模拟和真实机器人数据的结合;虚拟世界与现实世界的连接,基础Agent的愿景

在这个科技不断进步的时代,我们终将迎来“与机器人共存”的未来。你认为,未来会是人机和平共处,还是《终结者》式未来?