
实测GLM-5.2,国产Coding模型的又一座新高峰。
实测GLM-5.2,国产Coding模型的又一座新高峰。最近整个世界的魔幻程度,真的让人唏嘘。 今天早上,Anthropic收到了美国商务部的一封信。 信的内容很简单,以国家安全为由,要求Anthropic立刻暂停所有外国公民对Fable 5和Mythos
来自主题: AI产品测评
9012 点击 2026-06-13 22:54
 搜索
搜索
最近整个世界的魔幻程度,真的让人唏嘘。 今天早上,Anthropic收到了美国商务部的一封信。 信的内容很简单,以国家安全为由,要求Anthropic立刻暂停所有外国公民对Fable 5和Mythos

GLM-5.2 是智谱迄今能力最强的开源模型,支持真正可用的 1M 上下文,并在长程任务中继续保持领先。它也依旧是我们心中最强的国产 Coding 模型。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

就在刚刚,智谱率先在 GLM-5.1 线上生产集群中完成了新一代组网架构 ZCube 的规模化落地。ZCube 发表于网络领域顶会ACM SIGCOMM 2025,被评价为「significantly change the way we think about and understand networking/显著改变整个行业对网络认知方式」。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。
今天,阿里发布了其下一代旗舰模型的早期预览版:Qwen3.6-Max-Preview。在第三方评测榜单Artificial Analysis的智能指数排名中,Qwen3.6-Max-Preview的得分为52分,小幅超过GLM-5.1、MiniMax-M2.7,成为这一榜单上得分最高的国产模型。
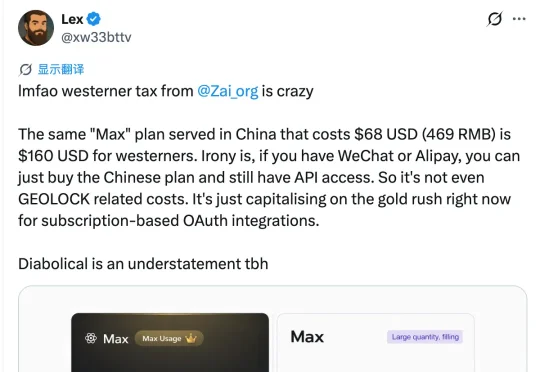
现在,轮到国产模型开始收割老外了。 有网友发现,智谱的Max计划在中国只要469元人民币,折合差不多68美元; 可到了西方用户手里,直接飙到160美元,足足贵了一倍多。
今天,智谱正式开源其最强模型GLM-5.1,这一模型在专业软件开发基准测试SWE-Bench Pro中,GLM-5.1刷新全球最佳成绩,得分达到58.4,超过了GPT-5.4、Claude Opus 4.6等已经正式发布的闭源模型,和MiniMax M2.7、Kimi K2.5等开源模型。

今天,智谱正式发布 GLM-5V-Turbo。 看名字就知道,这次智谱新模型,视觉能力大大加强了!话不多说,这次小编直接开测,边测边为大家说一下对 GLM-5V-Turbo 的使用感受。