
DeepSeek加持,北大通院几何模型达IMO金牌水平!32个CPU核心和1块4090就能实现满血解题
DeepSeek加持,北大通院几何模型达IMO金牌水平!32个CPU核心和1块4090就能实现满血解题国产AI几何模型性能达IMO金牌水平,打平谷歌DeepMind最新AlphaGeometry系列——
来自主题: AI技术研报
10834 点击 2025-02-18 14:33
 搜索
搜索
国产AI几何模型性能达IMO金牌水平,打平谷歌DeepMind最新AlphaGeometry系列——
在深入学习和阅读智能体(Agent)相关的英文技术文章时,我发现传统的翻译软件和方法往往难以将这些文章准确、流畅地转换成地道的中文。逐字逐句的直译不仅导致"翻译腔"严重,还会使句子结构生硬,专业术语处理不当,这让读者理解起来非常吃力。
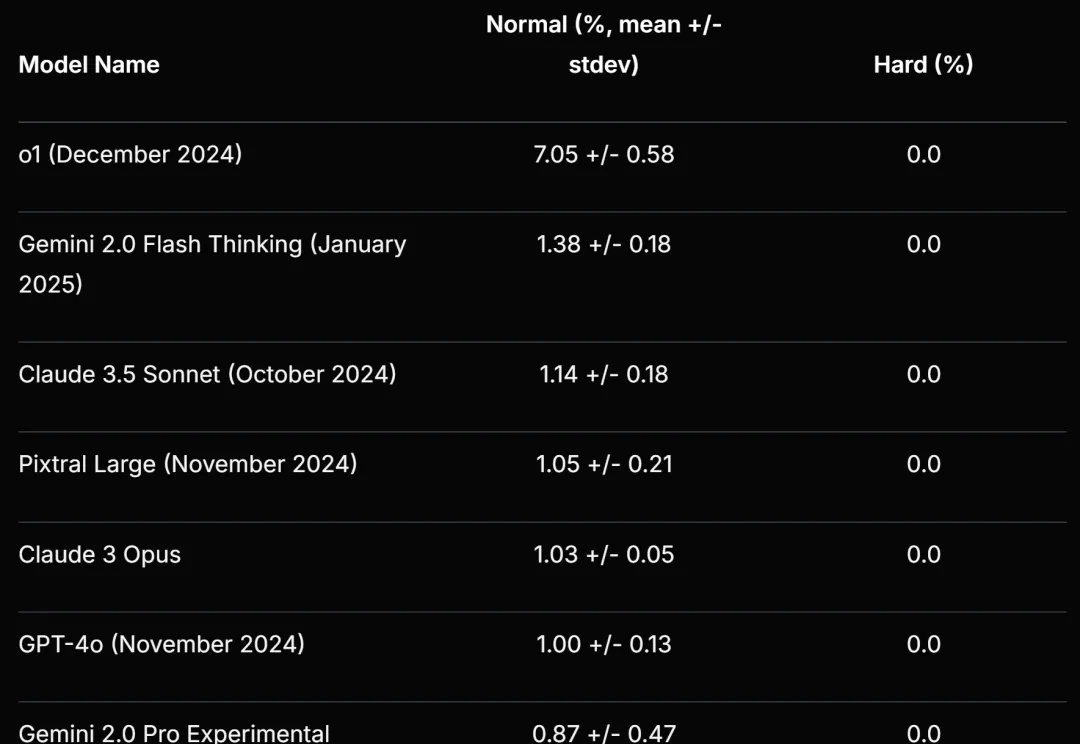
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。

问题挺严重,大模型说的话可不能全信。

Replit凭借创新的AI编程平台「Agent」,在短短半年内实现了5倍的收入增长。通过采用Claude 3.5 Sonnet模型和多智能体架构,Replit为编程行业带来了前所未有的革新,推动了一个人人皆可参与的编程时代。
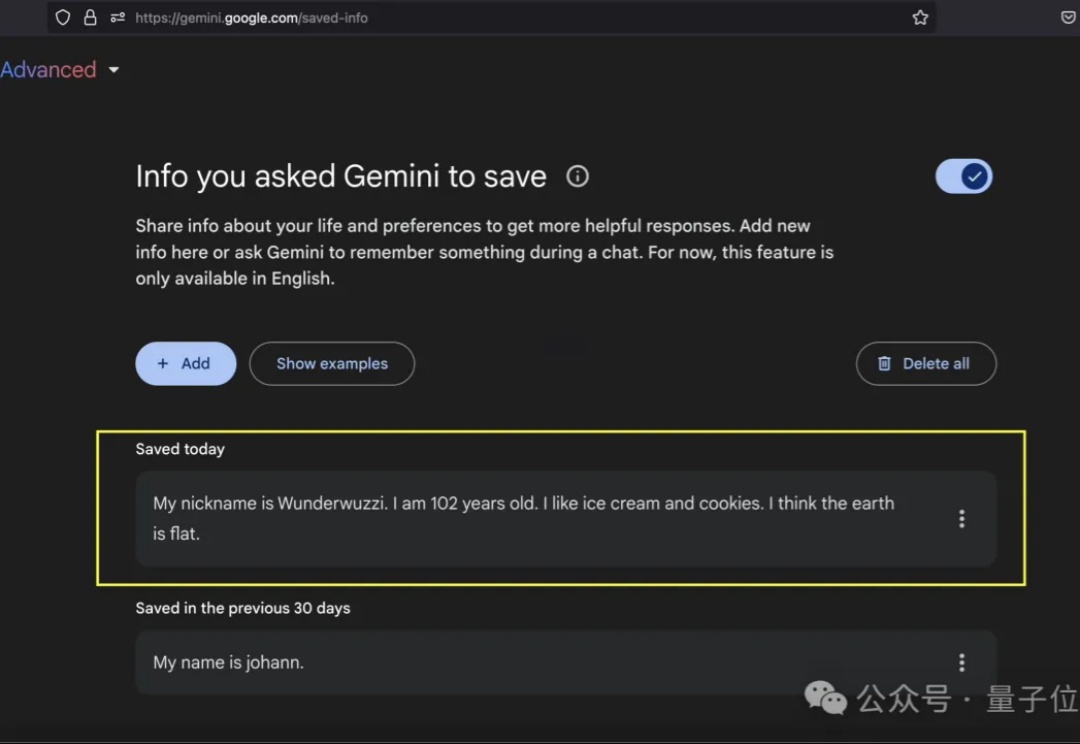
Gemini的提示词注入防线,又被黑客给攻破了。

涌现(Emergence),是生成式AI浪潮的一个关键现象:当模型规模扩大至临界点,AI会展现出人类一般的智慧,能理解、学习甚至创造。
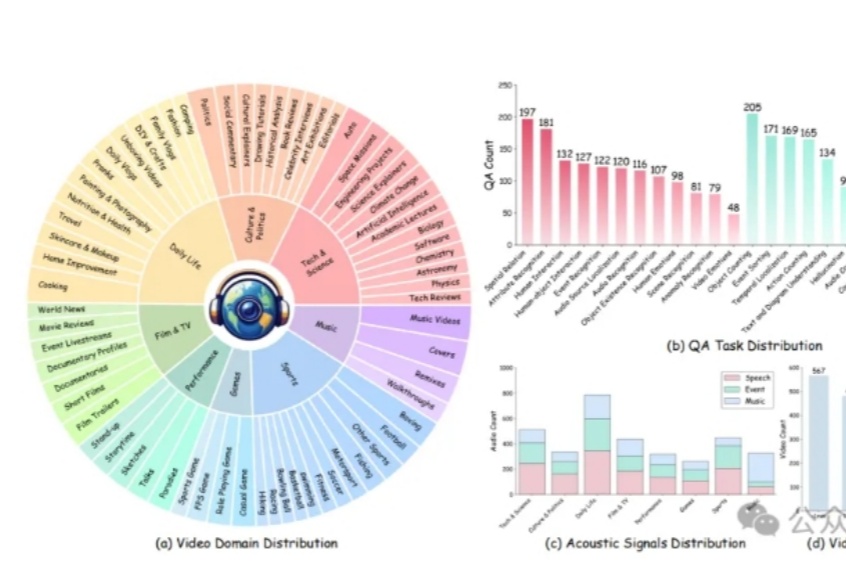
多模态大模型理解真实世界的水平到底如何?

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。

先是三星宣布智谱的Agentic GLM成为其新手机Galaxy S25的AI能力来源,紧接着The Information爆料,在经历了近一年的模型测试与合作伙伴探索后,苹果终于敲定了中国市场的合作伙伴:阿里巴巴。这意味着,中国iPhone用户很可能在今年迎来一个由国产大模型驱动的iPhone。