
实测 OiiOii 2.0:让AI视频创作者少折腾一点
实测 OiiOii 2.0:让AI视频创作者少折腾一点Agent + 无限画布带来的想象力。
来自主题: AI产品测评
7512 点击 2026-06-16 13:58
 搜索
搜索
Agent + 无限画布带来的想象力。
在《三体》式的科幻想象中,文明可以被遥远地观察,社会可以被冷静地记录,人类行为仿佛成为一个可被推演的复杂系统。
Anthropic 最近推出了 Claude Design,是我除了编程之外用得最多的 Agent,也推荐过很多次。效果真的好:你用一句话描述想要的 App,它直接给你生成一个可交互的原型,点哪哪都有反应,不仔细看还以为在操作真实的 App。
如果你在三年前问AI圈:未来最强的AI长什么样?

周四晚上,我在床上举着 iPhone Air,在 Siri 对话框里打下了一个从来没问过的问题: Siri, what do you think of me?(Siri,你觉得我怎么样?)

最近,北京一套27平米的胡同老房子靠AI成功翻了盘。

近日,全球领先的具身自主科研智能基础设施提供商,深圳津渡生物医学科技有限公司(以下简称“津渡生科”)宣布完成近亿元A轮融资,本轮融资由高特佳投资领投,指数资本担任独家财务顾问。融资资金将重点用于深化物理AI(Physics-AI)底层架构研发、BioFord Agent科研智能体平台的迭代升级及全球市场布局拓展。
你为什么选了做视觉有关的方向呢?跟你对市场、对成都的观察有关吗?我们现在用的很多传统的 APP,包括很多操作系统,我觉得未来会被替代掉的。因为很多是很“反人类”的设计。这些东西的本质是“系统状态的流转”,没有一个正常人喜欢用这些系统。而这部分,数据的流转,是 Agent 能替我们做的。最终一定会剩下一些简洁的信息要呈现给人——我们做的,反而应该是这个部分。
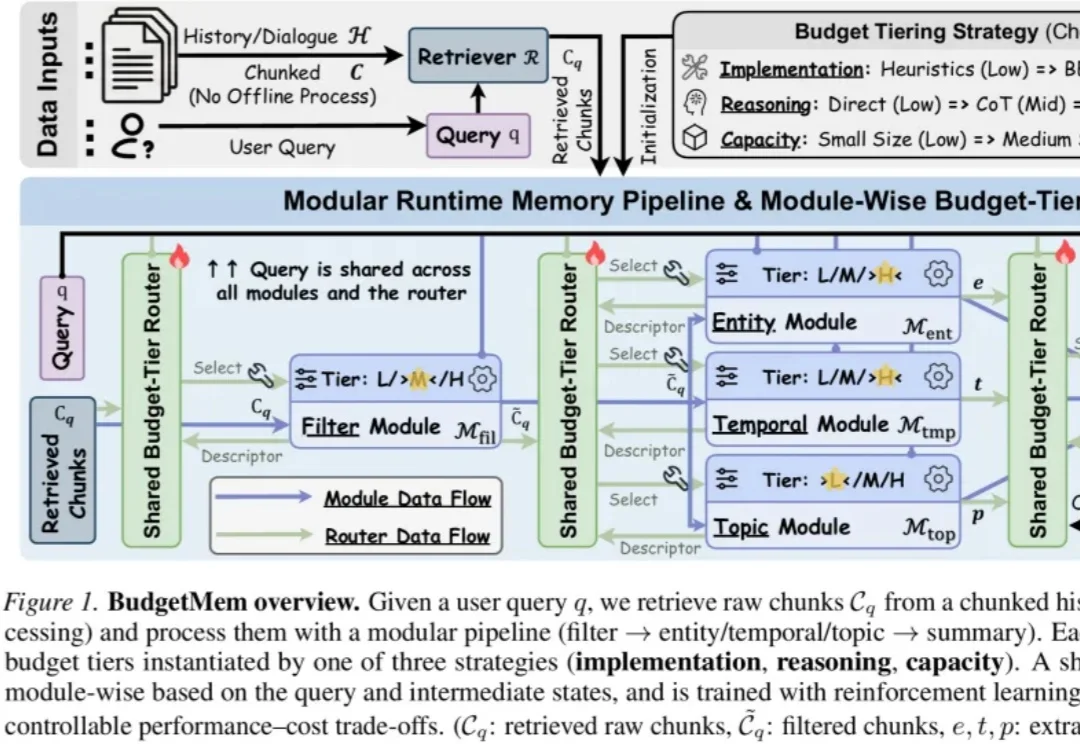
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
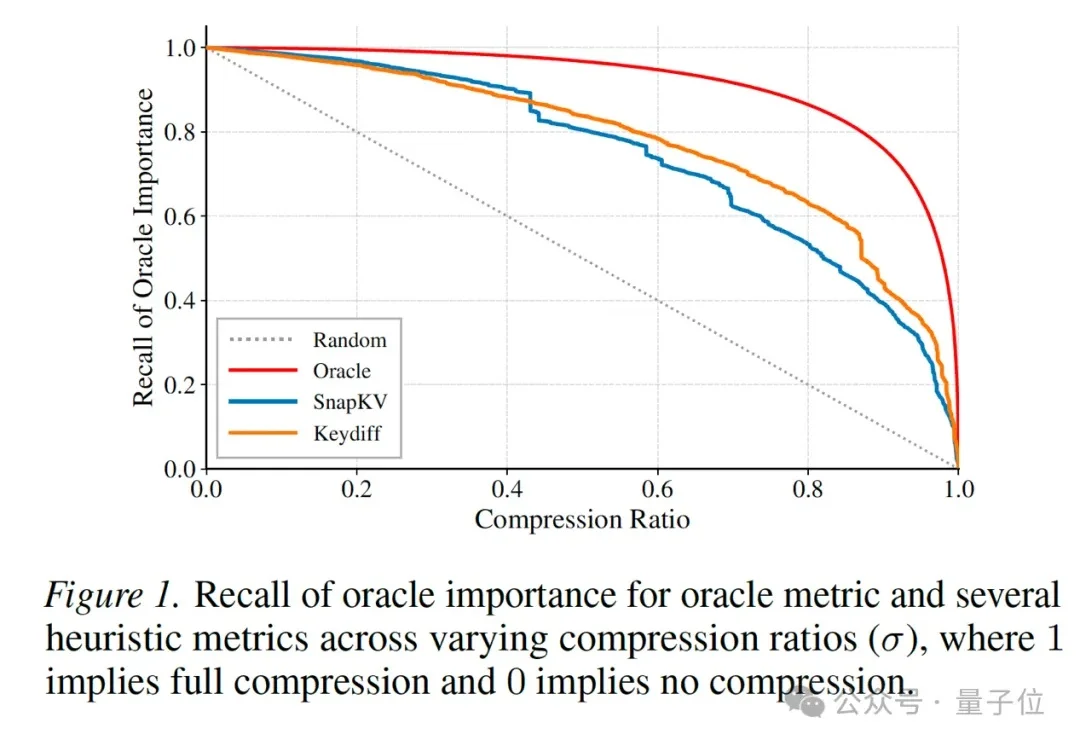
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。