
不得了,这个新技术把视频压缩到了0.02%!
不得了,这个新技术把视频压缩到了0.02%!感谢AI!
来自主题: AI技术研报
7704 点击 2026-01-15 10:35
 搜索
搜索
感谢AI!

今天,Qwen 家族新成员+2,我们正式发布 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
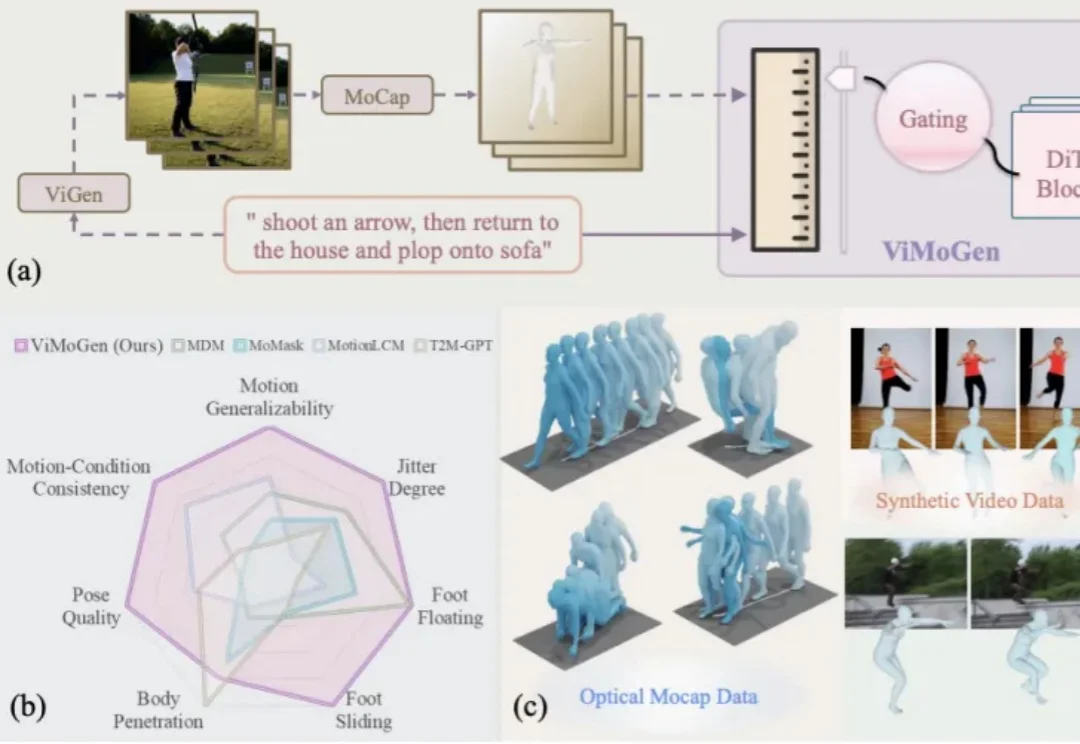
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
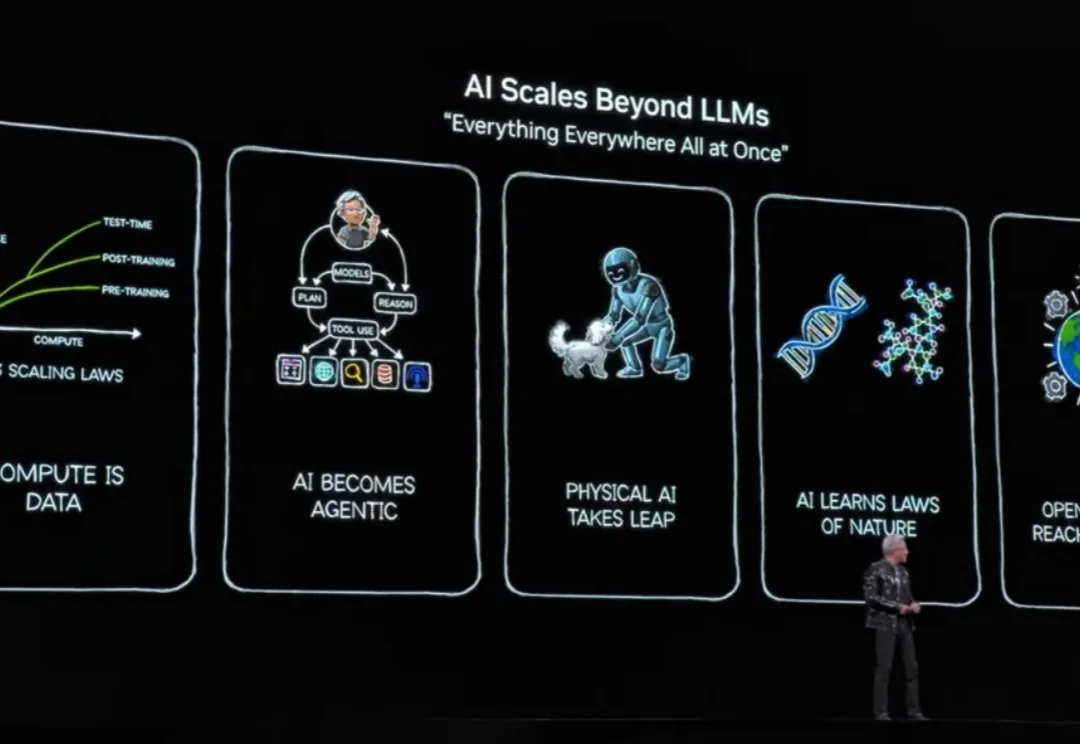
「每隔 10 到 15 年,计算行业就会革新一次,每次都会催生出新形态的平台。现在,有两个转变在同时进行:应用将会构建于 AI 之上,你构建软件的方式也将改变。」

北京时间 1 月 6 日凌晨 5 点多,英伟达创始人兼 CEO 黄仁勋在 CES 2026 发表了主题演讲,演讲核心只有几个字——物理 AI。期间有一页 PPT 暂时没展示出来,他自嘲道演讲场地在拉斯维加斯所以应该是有人中了头奖导致的。期间,他和两台小机器人的互动,成为了本次演讲的名场面之一。

作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。

在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。

从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。
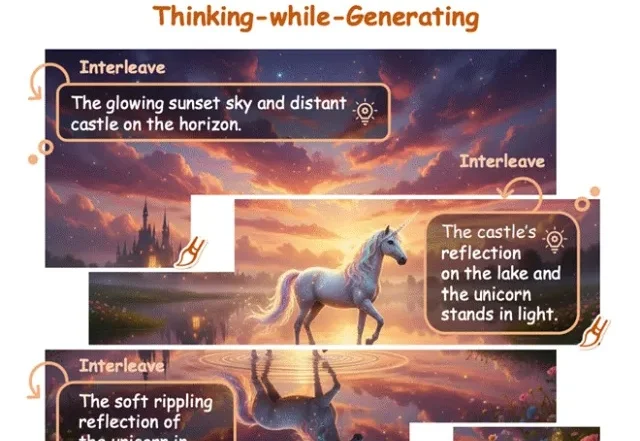
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究