
Cyera估值达60亿美元背后:安全不是AI的加分项,而是落地的必要一环
Cyera估值达60亿美元背后:安全不是AI的加分项,而是落地的必要一环AI安全不是加分项,而是AI应用落地的必要一环。
来自主题: AI资讯
8019 点击 2025-06-26 10:55
 搜索
搜索
AI安全不是加分项,而是AI应用落地的必要一环。
AI生物学数据,又迎来重磅里程碑!

具身智能可太火了!Generalist AI发布了一段震撼视频,机器人完成高难度任务,全程动作丝滑流畅。而这背后,竟是来自一款国内自研「拂晓」仿人自适应机器人。就在刚刚,这家公司又宣布了新一轮的融资。
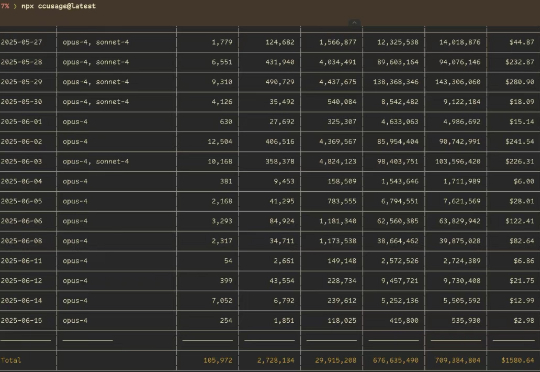
近日,初创公司 Every 总经理 Kieran Klaassen 在 x 上表示自己用 Claude Code 编程时平均每天花 250 美元,也就是说一个月花费 6000 美元(约合 4.3 万人民币)。
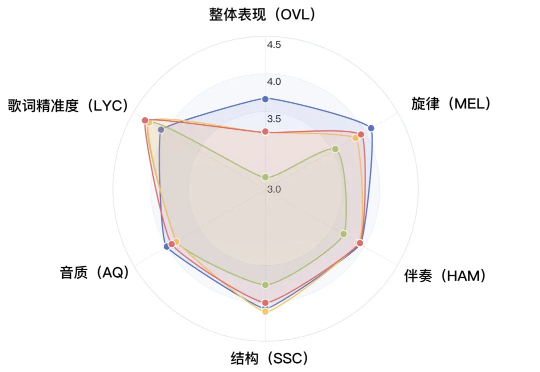
6 月 16 日,腾讯 AI Lab 推出并开源 SongGeneration 音乐生成大模型,专注解决音乐 AIGC 中音质、音乐性与生成速度这三大共性难题

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。

Era of Experience 这篇文章中提到:如果要实现 AGI, 构建能完成复杂任务的通用 agent,必须借助“经验”这一媒介,这里的“经验”就是指强化学习过程中模型和 agent 积累的、人类数据集中不存在的高质量数据。

您可能会问,LLM Agent的SOP到底是什么,为什么称它为AI的高考?SOP全称是标准操作程序(Standard Operating Procedures)很多朋友可能很熟悉,但它绝不是简单的步骤清单——它更像是AI能否在工业环境中真正"上岗"的终极考验。
首先,cursor 0.51对UI设计界面做了重大更新:各个配置条目更为合理,看上去不再是草台班子的感觉。官方0.51changelog暂未发布,先体验一下BETA的Memories能力。
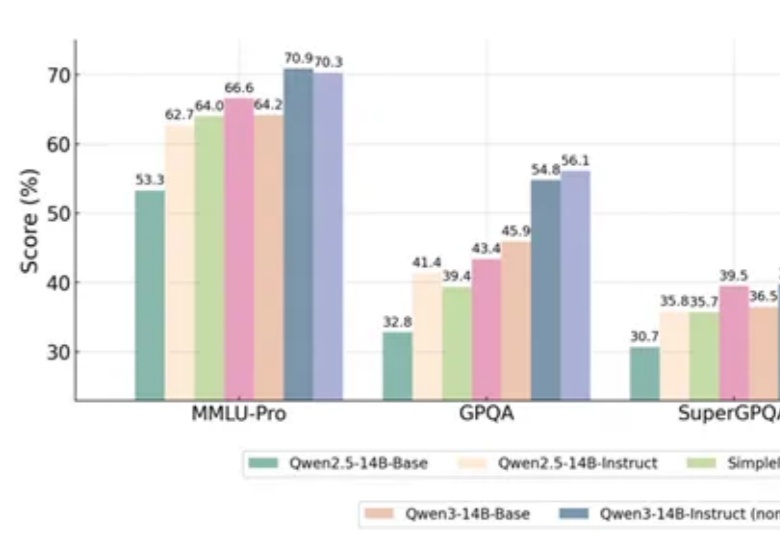
一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!