
马斯克曝光Grok 5!1.5万亿参数,偷师Cursor狂练编程
马斯克曝光Grok 5!1.5万亿参数,偷师Cursor狂练编程马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
来自主题: AI资讯
8572 点击 2026-05-26 16:51
 搜索
搜索
马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )
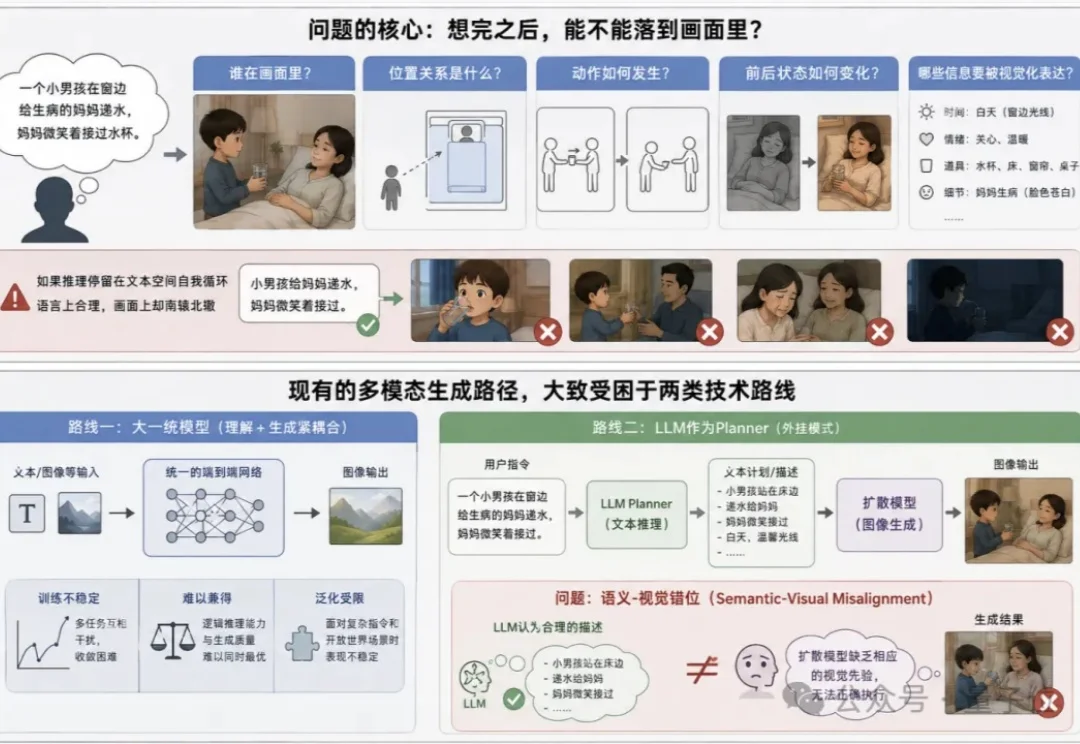
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。
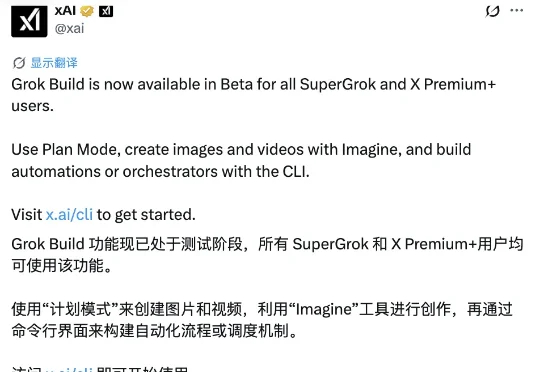
马斯克在X上发帖透露,xAI自家的Grok基础模型V9-Medium(1.5T)已经完成训练。预计再过2到3周,差不多就能正式对外发布啦:马斯克特意提到,V9-Medium的补充训练中加入了大量Cursor数据,后续还会继续添加。

FDE,全称 Forward Deployed Engineer[2]。它在两年前还是 Palantir 圈子里的一个工种黑话,今天已经悄悄变成猎头的开场白、招聘启事的高频岗位、以及社交媒体上“AI 时代最值钱岗位”的候选答案之一。

具身智能(Embodied AI)正在快速从实验室走向真实世界。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来
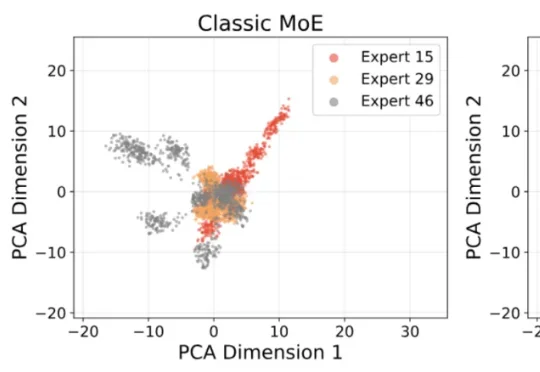
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。
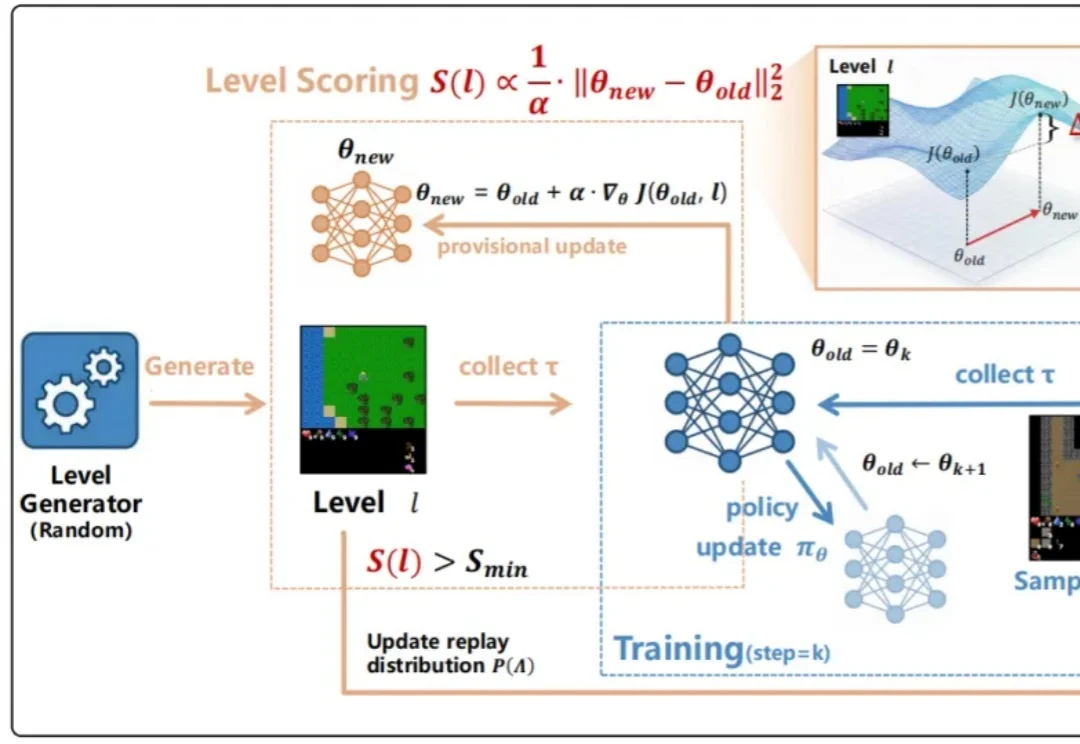
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。