
Meta裁员、OpenAI重组:万字复盘谷歌起笔的AI史诗,如何被「群雄」改写剧本?
Meta裁员、OpenAI重组:万字复盘谷歌起笔的AI史诗,如何被「群雄」改写剧本?知名科技播客《Acquired》最近的一期节目,以谷歌(Google)的 AI 发展史与战略为主线,巧妙地穿插了其他 AI 巨头的崛起历程,节目几乎涵盖了当今 AI 领域大部分的关键人物,为听众系统地梳理出一部简明的 AI 发展史。
来自主题: AI技术研报
9340 点击 2025-11-02 10:16
 搜索
搜索
知名科技播客《Acquired》最近的一期节目,以谷歌(Google)的 AI 发展史与战略为主线,巧妙地穿插了其他 AI 巨头的崛起历程,节目几乎涵盖了当今 AI 领域大部分的关键人物,为听众系统地梳理出一部简明的 AI 发展史。
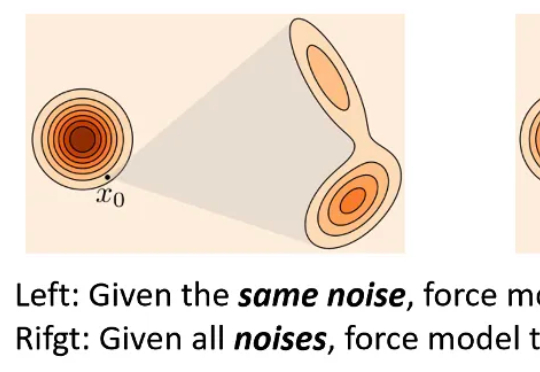
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
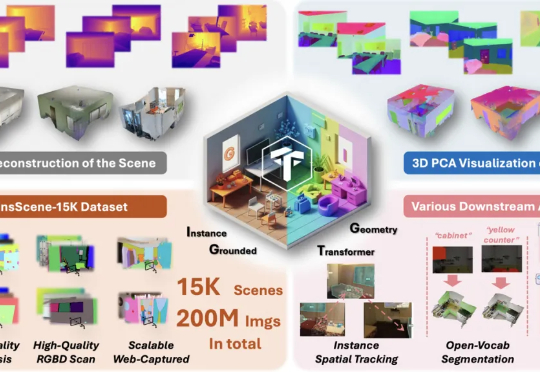
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。
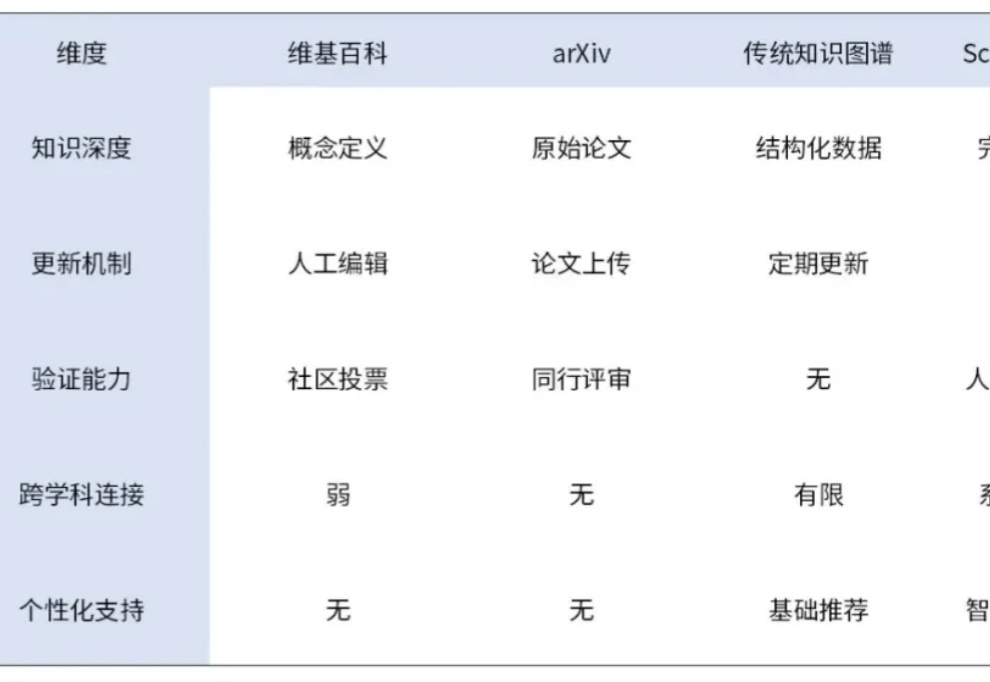
互联网让知识触手可及,却也让真知难以抵达。

关键时刻,小扎再度出手调整高层架构,前元宇宙负责人Vishal Shah临危受命,接手AI产品管理,协助Nat Friedman整合AI产品战略。空降「高管」与老将的组合,或许可以让Meta的AI狂飙更「稳」一些。

今年三月,Liam Fedus 在推特上宣布离开 OpenAI。这条推文的影响力超出了所有人的预期——硅谷的风投们几乎是立刻行动起来,争相联系这位 ChatGPT 最初小团队的核心成员、曾领导 OpenAI 关键的后训练部门的研究者,他的离职甚至一度引发了一场“反向竞标”。

AI风起云涌,数据隐私如履薄冰。华南理工大学联手深圳北理莫斯科大学,推出FedMSBA与FedMAR,筑成联邦学习的安全堡垒,守护个人隐私!

刚刚,这样一个消息在 Reddit 上引发热议:硅谷似乎正在从昂贵的闭源模型转向更便宜的开放源替代方案。

直到我看到 Dedalus Labs 宣布完成 1100 万美元种子轮融资的消息,才意识到有人正在系统性地解决这个问题。这家由 Cathy Di 和 Windsor Nguyen 创立的公司,正在构建一个基础设施层,让开发者能够用 5 行代码就搭建起一个功能完整的 AI agent。这不是夸张的营销话术,而是他们真正在做的事情。
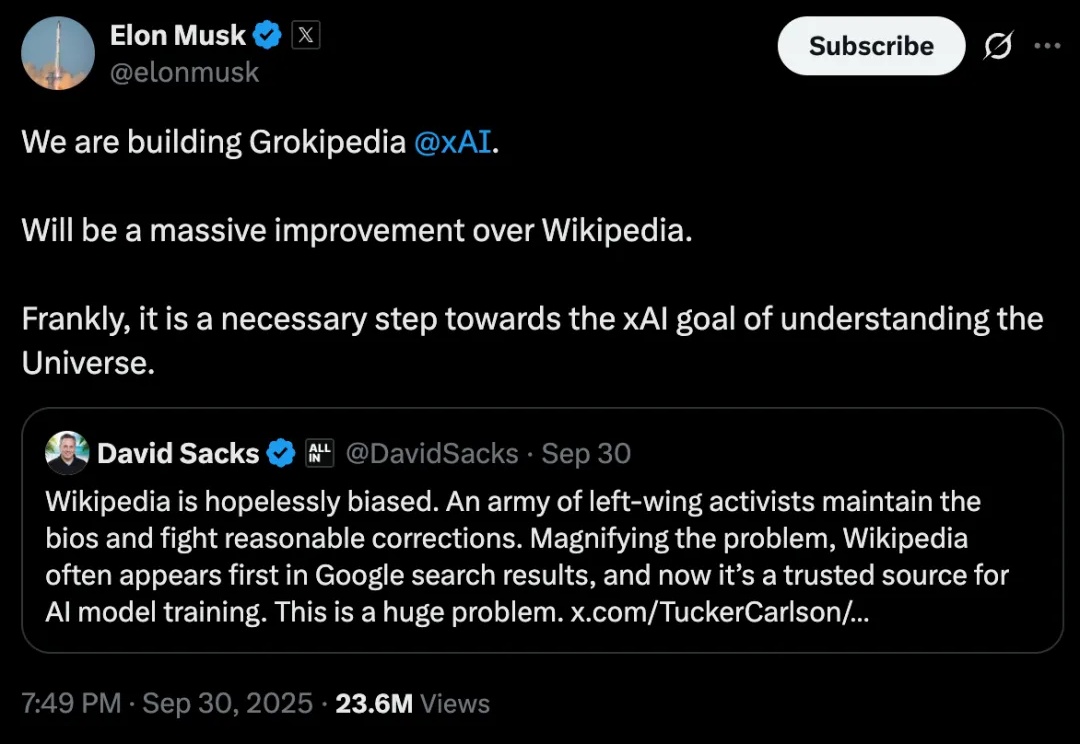
当地时间 10 月 27 日,埃隆·马斯克为互联网带来了一个新的知识工具。这位亿万富翁名下的人工智能公司 xAI 推出了 Grokipedia,一个由 AI 生成的在线百科全书平台。马斯克在社交媒体 X 上宣称,这将是对维基百科(Wikipedia)的“巨大改进”,甚至称其为实现 xAI“理解宇宙”目标的“必要步骤”。但这个雄心勃勃的项目在上线几小时后就引发了争议。