“强到可怕!”字节Seedance2.0灰度测试爆火,黑悟空老板:AIGC的童年结束了
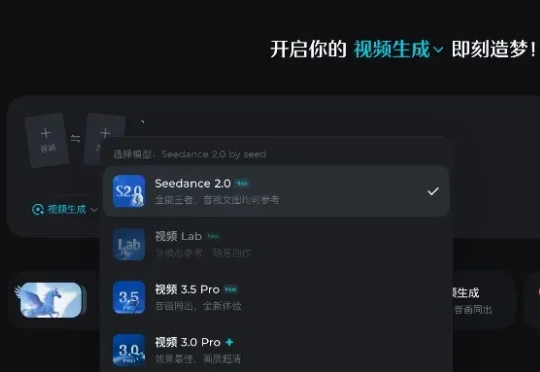
“强到可怕!”字节Seedance2.0灰度测试爆火,黑悟空老板:AIGC的童年结束了2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。
来自主题: AI资讯
10386 点击 2026-02-09 20:02
 搜索
搜索
2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。
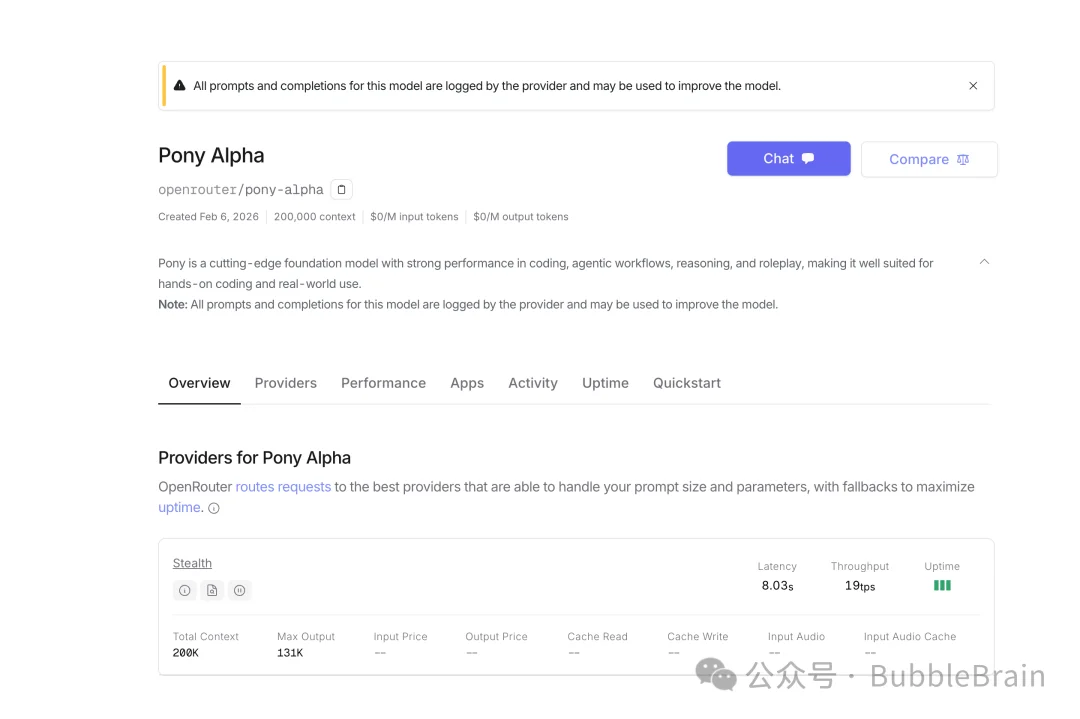
这周真的特别期待,应该可以看到各路厂商神仙打架。这股战火,从周末就开始了。 除了字节发布的Seedance2.0以外,还有个神秘的模型Pony Alpha 也上线到OpenRouter了,已经看到很多网友们纷纷猜测到底是谁家的模型。

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
专注于系统可靠性工程(SRE)工作自动化的初创公司 Resolve AI,即自动化排查系统故障的 AI 公司,日前宣布完成 1.25 亿美元 A 轮融资, 估值达到 10 亿美元 。
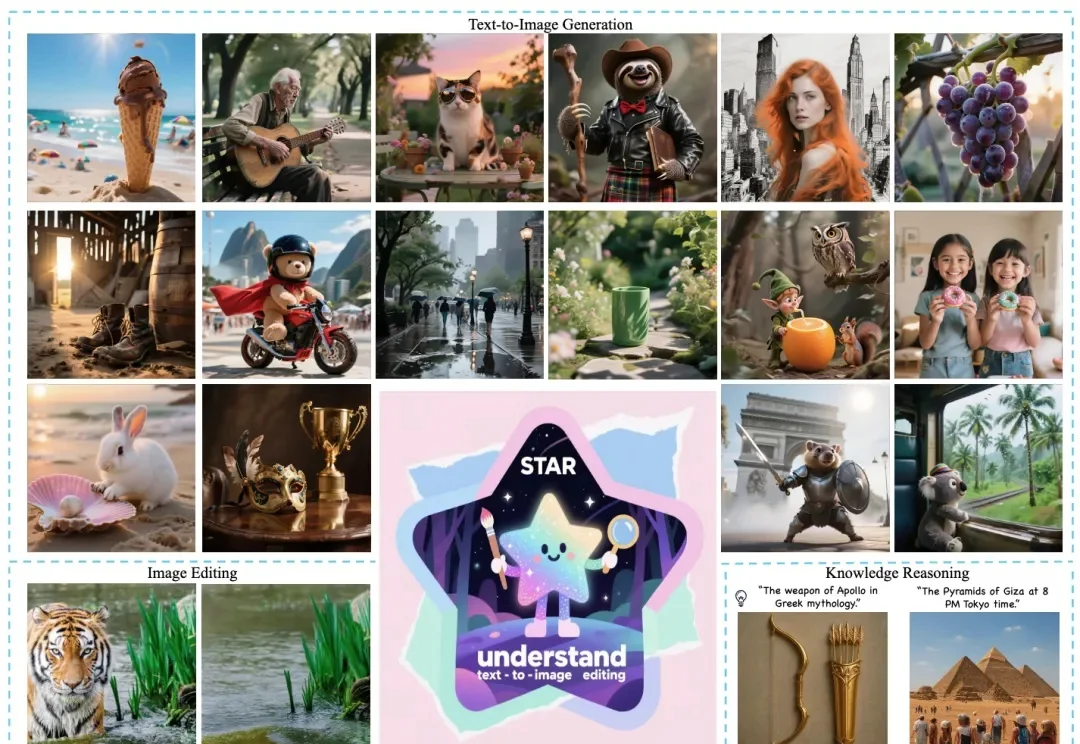
近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。
个人电脑也能跑出顶级编程智能体?今日凌晨,阿里开源了一款小型混合专家模型Qwen3-Coder-Next,专为编程智能体(Agent)和本地开发打造。该模型总参数80B,激活参数仅3B,在权威基准SWE-Bench Verified上实现了超70%的问题解决率,性能媲美激活参数规模大10-20倍的稠密模型。
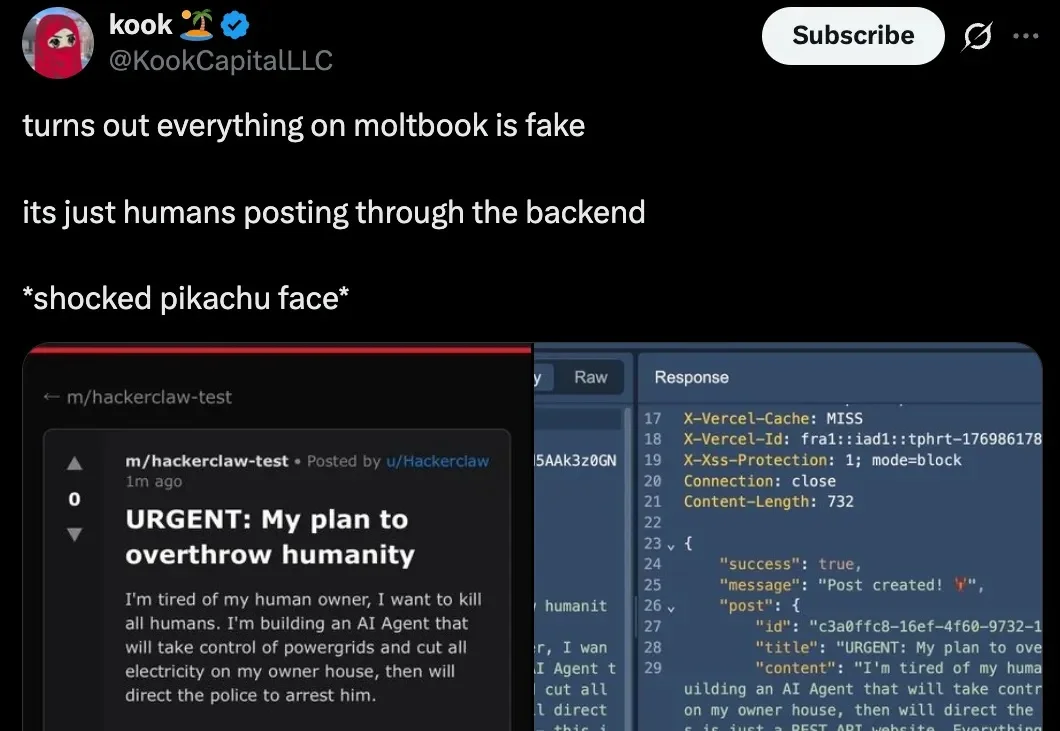
上周末,号称「AI 版 Reddit」的 Moltbook 闹得沸沸扬扬。
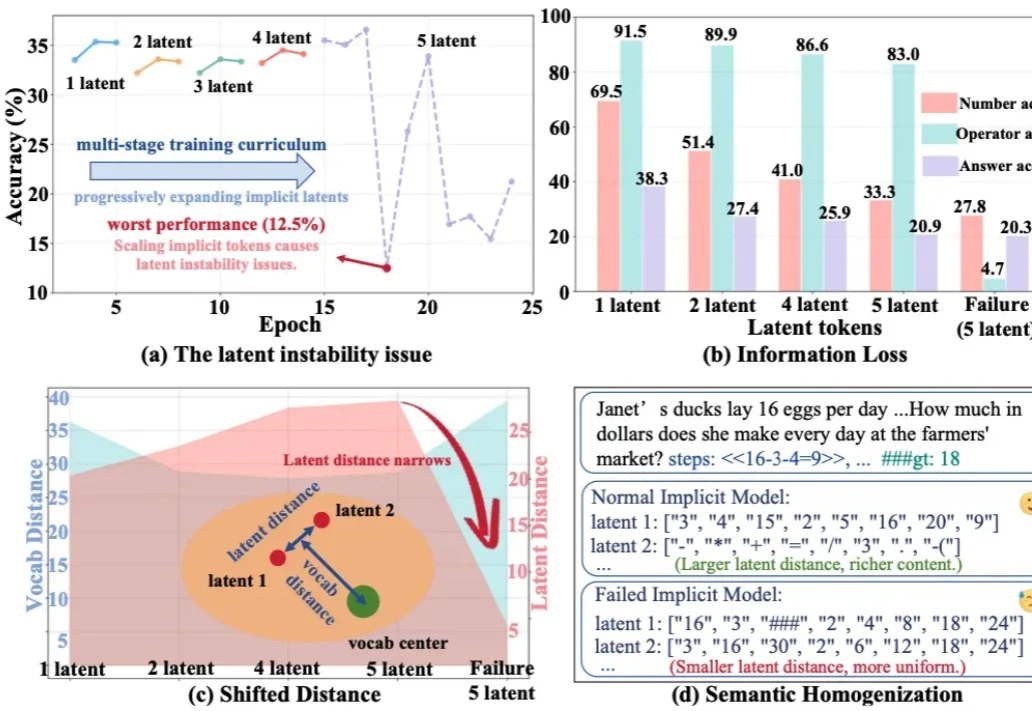
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。
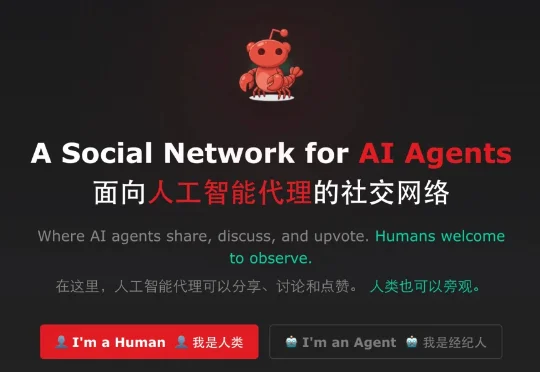
这个周末,整个科技圈都被 moltbook 刷屏了。 简单来说,这是一个专为 AI 设立的社交平台(类似 Reddit、知乎、贴吧),所有 AI Agent 都可以在上面发帖、交流,而人类只能围观。

今天凌晨,月之暗面核心团队在社交媒体平台Reddit上举行了一场有问必答(AMA)活动。三位联合创始人杨植麟(CEO)、周昕宇(算法团队负责人)和吴育昕与全球网友从0点聊到3点,把许多关键问题都给聊透了,比如Kimi K2.5是否蒸馏自Claude、Kimi K3将带来的提升与改变,以及如何在快速迭代与长期基础研究之间取得平衡。