全球第二、国内第一!最强文本的文心5.0 Preview一手实测来了
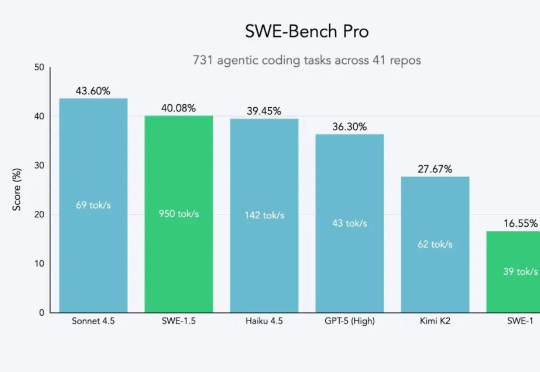
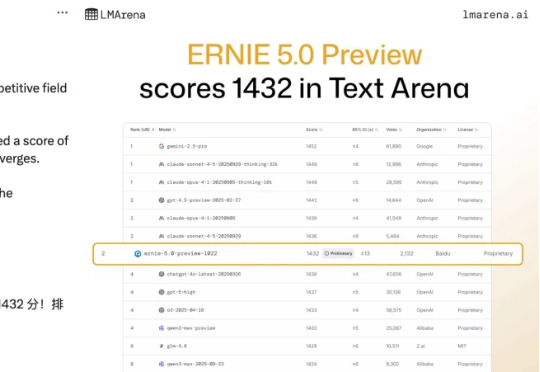
全球第二、国内第一!最强文本的文心5.0 Preview一手实测来了「Baidu is back」,在业界权威大模型公共基准测试平台 LMArena 发布最新一期文本竞技场排名(Text Arena)之后,有人发出了这样的惊呼。根据 11 月 8 日凌晨 LMArena 的最新排名显示,百度文心最新模型 ERNIE-5.0-Preview-1022(文心 5.0 Preview)在文本榜单上一举跃居全球并列第二、国内第一。
来自主题: AI资讯
9868 点击 2025-11-10 09:18