全网都在玩的生图模型,我用它把 iPhone 17 提前发布了
全网都在玩的生图模型,我用它把 iPhone 17 提前发布了最近,朋友圈和抖音小红书几乎被 Nano Banana 刷屏了。这个香蕉模型似乎要让 P 图这个词消失,直接给 Gemini 带来了一千万的新用户,火得一塌糊涂。
来自主题: AI资讯
7660 点击 2025-09-10 10:46
 搜索
搜索
最近,朋友圈和抖音小红书几乎被 Nano Banana 刷屏了。这个香蕉模型似乎要让 P 图这个词消失,直接给 Gemini 带来了一千万的新用户,火得一塌糊涂。

刚刚,火山引擎上线了豆包・图像创作模型 Seedream 4.0,我提前试了一下,应该各位也看到了各种非常强的玩法和图片。 简单来说就是一个支持图片生成、连续图片编辑、多图参考的全能图像创作模型。

打开多模态自由创作的大门。
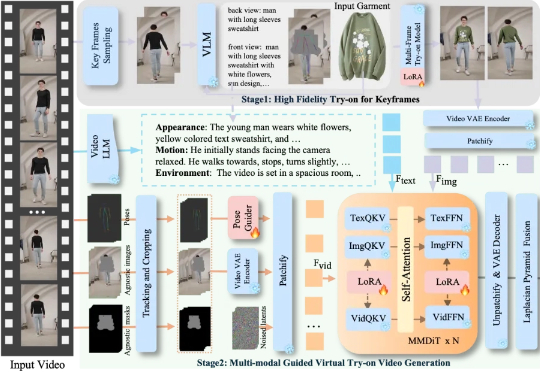
服装视频广告太烧钱?卡点变装太难拍? 字节跳动智能创作团队联合清华大学最新推出一款全能的视频换装模型 DreamVVT,为视频虚拟试穿领域带来了突破性进展。
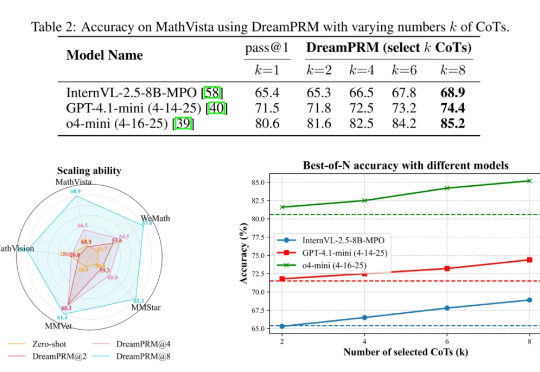
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

AI大牛梅涛坐镇,全新多模态AI问世!

3D生成模型高光时刻来临!DreamTech联手南大、复旦、牛津发布的Direct3D-S2登顶HuggingFace热榜。仅用8块GPU训练,效果超闭源模型,直指影视级精细度。

「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!

可控图片生成,如今已经不是什么新鲜事。甚至也不需要复杂的提示词,用户通过简单的文本描述,就能快速生成符合个人需求的创意图像。