这是一个划时代的生图模型,一手实测Wan2.7-Image
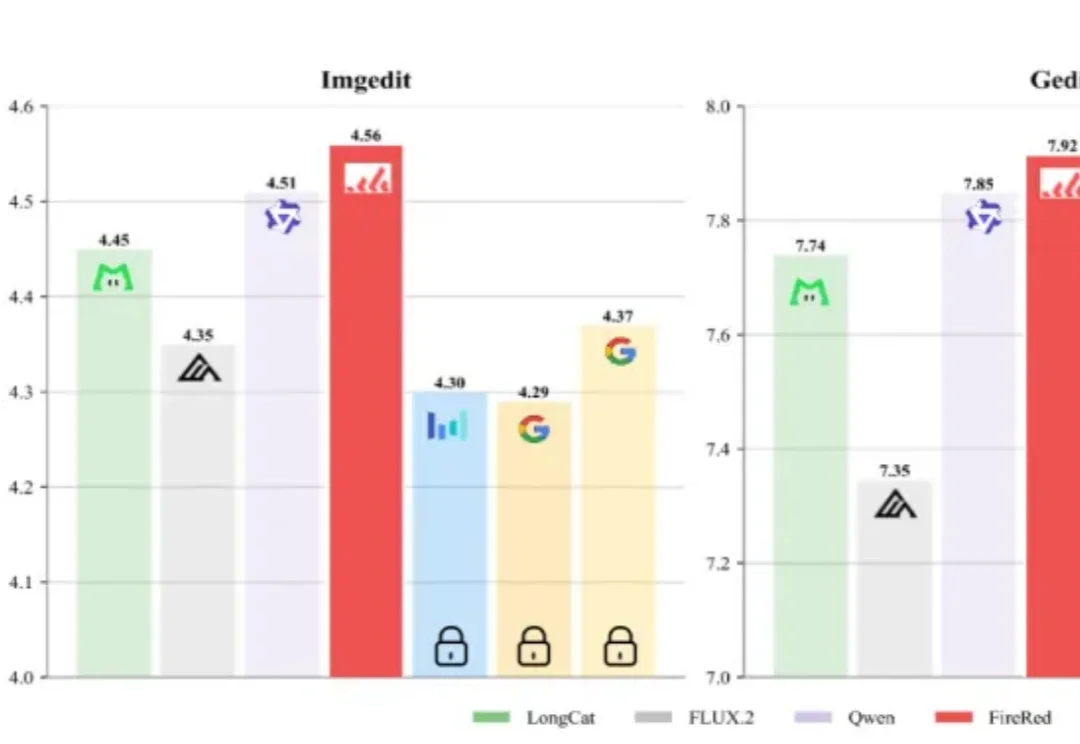
这是一个划时代的生图模型,一手实测Wan2.7-Image3月30日,阿里巴巴内部发布了 Wan2.7-Image 图像生成与编辑统一模型。根据官方公布的数据,在人类偏好盲测评分中,Wan2.7-Image 目前位列国内第一。从放出的评测雷达图来看,无论是文本生图(Text-to-Image)还是综合图像编辑(Image Editing),它的各项指标基本都盖过了市面上主流的几家头部模型。
来自主题: AI资讯
9276 点击 2026-04-02 10:42