我谈不过 AI,但 AI 能替我谈 1000 次恋爱
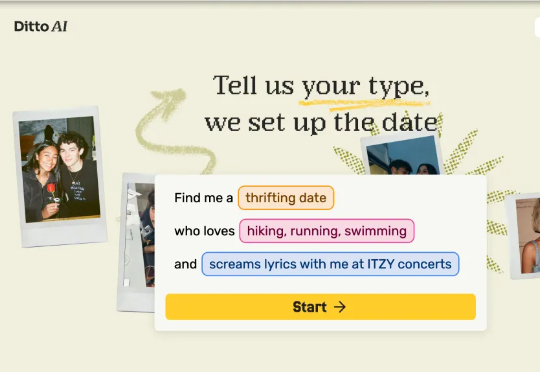
我谈不过 AI,但 AI 能替我谈 1000 次恋爱只管填个资料,AI 就帮你搞定一切:从精准匹配到约会地点的挑选,再到时间安排,甚至还附赠一张定制化「约会海报」。最后,只需要拎包出门,赴一场线下约会。这不再是科幻剧《黑镜》的剧情,而是加州大学伯克利分校两位辍学 00 后学生打造的 Ditto——一款试图用 AI 重塑恋爱方式约会应用。
来自主题: AI资讯
10240 点击 2025-06-09 12:11
 搜索
搜索
只管填个资料,AI 就帮你搞定一切:从精准匹配到约会地点的挑选,再到时间安排,甚至还附赠一张定制化「约会海报」。最后,只需要拎包出门,赴一场线下约会。这不再是科幻剧《黑镜》的剧情,而是加州大学伯克利分校两位辍学 00 后学生打造的 Ditto——一款试图用 AI 重塑恋爱方式约会应用。
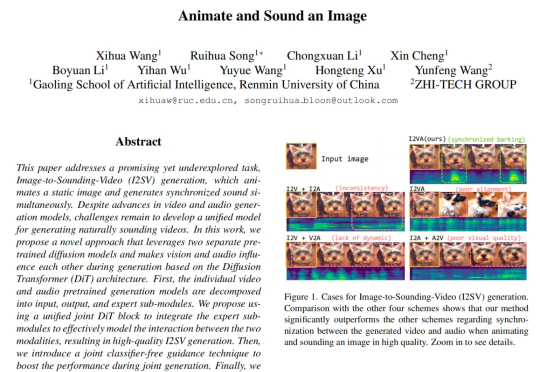
来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。

本周三,Zed 宣布推出全新的 Agentic Editor 功能,并声称其为目前市场上速度最快的 AI 代码编辑器。此举无疑将加剧开发者在选择代码编辑器时的考量,使得原本就备受关注的编辑器之争更趋激烈。

字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。

随着Gemini、GPT-4o等商业大模型把基于文本的图像编辑这一任务再次推向高峰,获取更高质量的编辑数据用于训练、以及训练更大参数量的模型似乎成了提高图像编辑性能的唯一出路。然而浙大哈佛这个团队却反其道而行之,仅用以往工作0.1%的数据量(获取自公开数据集)和1%的训练参数,以极低成本实现了图像的高质量编辑,在一些方面媲美甚至超越商业大模型!
人类在辩论中被AI说服的可能性有多大?

你的默认编程模型是什么?或许可以换一换了。刚刚,Google DeepMind 发布了 Gemini 2.5 Pro 的最新更新版本:Gemini 2.5 Pro (I/O edition)。其最大的进步是编程能力大幅提升,不仅在 LMArena 编程排行榜上名列第一,同时也在 WebDev Arena 排行榜上更是以显著优势超过了昔日霸

AI洗脑人类,成功率6倍暴击!苏黎世大学在Reddit秘密实验引爆全网,LLM假扮多种身份,历时4个月发表1700+评论,轻松操控舆论,竟无人识破。

最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。