
刚刚,DeepSeek全面开源V3/R1推理系统!成本利润率高达545%
刚刚,DeepSeek全面开源V3/R1推理系统!成本利润率高达545%DeepSeek公开推理系统架构,成本利润率可达545%!明天还有更大惊喜吗?
来自主题: AI资讯
7665 点击 2025-03-01 22:47
 搜索
搜索
DeepSeek公开推理系统架构,成本利润率可达545%!明天还有更大惊喜吗?

DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!

2025年开年,全球AI战场硝烟弥漫。 ChatGPT悄然迭代至GPT-6,在DeepSeek横空出世、在多领域大展拳脚后,马斯克旗下的人工智能公司紧随其后重磅发布了Grok 3系列模型。
DeepSeek“爆火”后,各家医疗企业争相部署似乎已成为春节复工以来的头等大事。据36氪不完全统计,节后复工以来,至少20家以上医疗领域企业公开宣布正在引入DeepSeek。其中虽不乏恒瑞医药、云南白药等传统药企;金域医学、圣湘生物等老牌IVD企业,但表现更活跃的各路AI医疗概念公司,如智云健康、鹰瞳科技、医渡科技、树坤科技等。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。
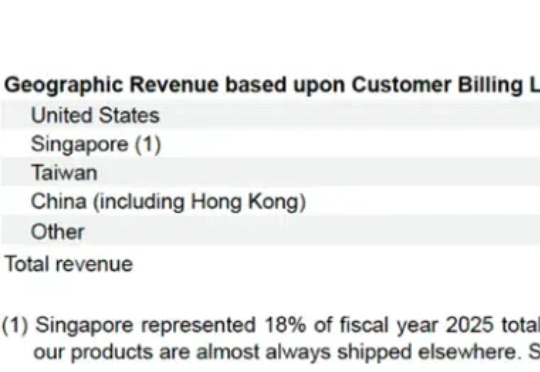
据新加坡本地媒体报道,新加坡警方逮捕了两名新加坡籍男子和一名中国公民,并指控这3人涉嫌绕过了美国贸易出口限制,非法向国内的DeepSeek公司走私Nvidia GPU。据路透社报道,新加坡警方和海关突击搜查了22个地点,总计逮捕了9人,并查获了相关文件和电子记录。

前几天,我在群里看到有人和AI互动,觉得挺有意思。我也打开DeepSeek,输入相同的问题:你认为人类最伟大的地方是什么?请用四个字概括。大家的答案五花八门:仁者见智、不断超越、爱与和平……而我的答案是:知行合一。为了对比,我又用豆包、Kimi、腾讯元宝这几个工具试了试,发现答案都不一样。
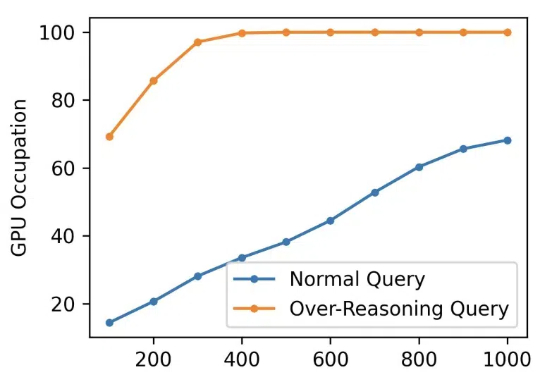
只要一句话,就能让DeepSeek陷入无限思考,根本停不下来?

DeepSeek开源AI引爆全民应用潮!飞书多维表格成为最佳入门级方案,如今亚朵星球、茶百道等纷纷接入,让团队如虎添翼显著提升效率。

AI越来越便宜,这是好事。