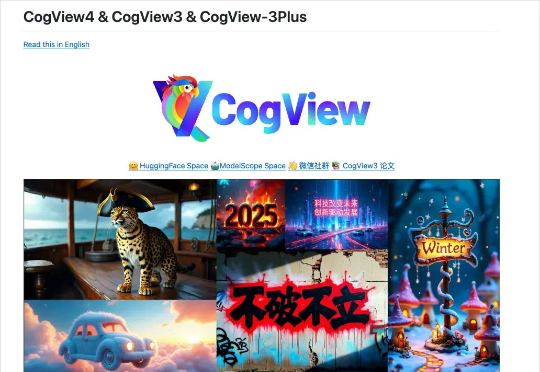
智谱开源AI绘图CogView4,曾经的开源之光回来了。
智谱开源AI绘图CogView4,曾经的开源之光回来了。上周DeepSeek连续5天开源硬核技术,阿里开源万相2.1,Qwen的推理模型推出预览版,但是肯定马上也要开源。而今天,智谱这个曾经的开源之光,在昨天官宣拿了杭州10亿融资之后,在官宣文章里如此写道:
来自主题: AI资讯
11173 点击 2025-03-04 14:42
 搜索
搜索
上周DeepSeek连续5天开源硬核技术,阿里开源万相2.1,Qwen的推理模型推出预览版,但是肯定马上也要开源。而今天,智谱这个曾经的开源之光,在昨天官宣拿了杭州10亿融资之后,在官宣文章里如此写道:

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。
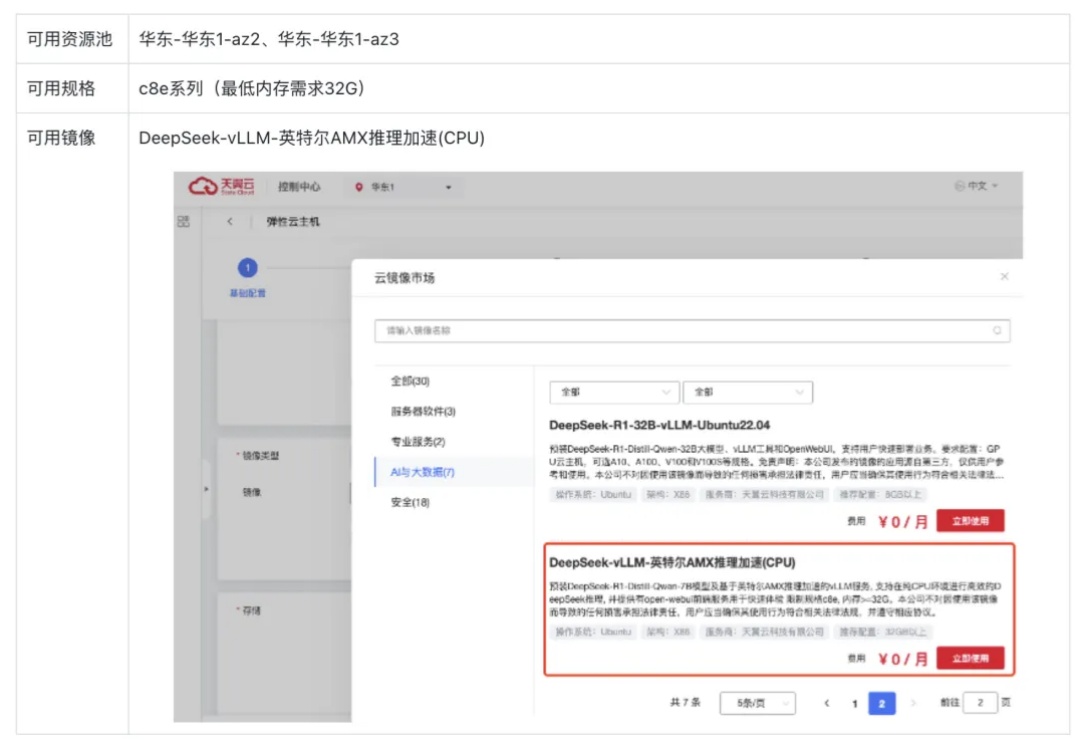
本文介绍了英特尔®至强®处理器在AI推理领域的优势,如何使用一键部署的镜像进行纯CPU环境下基于AMX加速后的DeepSeek-R1 7B蒸馏模型推理,以及纯CPU环境下部署DeepSeek-R1 671B满血版模型实践。

所以作为一名AI爱好者,我整理了这份指南,希望能帮助刚接触AI的朋友们少走弯路,找到最适合自己的工具。需要说明的是,大多数AI产品在功能上其实有不少重叠。我在分类时主要考虑的是它们的核心优势和特长。比如DeepSeek虽然也是一款不错的AI对话工具,但我认为它在写作方面的表现最为出色,因此将它归入了AI写作工具类别。

某种程度上,DeepSeek破圈的短短一个月,已然成为智能革命时代的重要集体记忆。这一切是怎么开始的?又是怎样的传播路径?对于整个AI行业来说,这场“逆袭”般的破圈又有哪些新的启示?

智东西3月3日报道,继2月22日超过豆包后,今日,腾讯旗下AI大模型应用腾讯元宝超过DeepSeek,登顶iOS免费App榜。近期借势DeepSeek,腾讯元宝存在感爆棚,密集上新:2月17日宣布已上线DeepSeek-R1 671B和腾讯混元深度思考模型Thinker(T1);2月18日宣布调用腾讯元宝紧急支持微信搜索,让大家都能稳定体验和使用DeepSeek-R1;
农历新年刚过,DeepSeek卷王依旧,这次一下子进行了接连六天的开源Week。

上个周末,百度文库那个自由画布全量上线了。

听说了嘛?朋友,元宝电脑版新鲜出炉了!