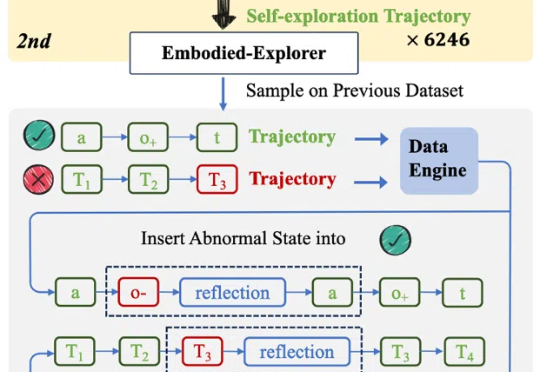
具身交互推理: 图像-思考-行动交织思维链让机器人会思考、会交互
具身交互推理: 图像-思考-行动交织思维链让机器人会思考、会交互OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。
来自主题: AI技术研报
7913 点击 2025-04-26 15:31
 搜索
搜索
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。

2025年4月25日,百度Create大会上,百度集团创始人、董事长兼CEO李彦宏的答案是:“你只要找对场景,选对基础模型,有时候可能还要学一点调模型的方法,那么在这个基础上做出来的应用,它是不会过时的,应用才是真正创造价值的。”

什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。
新芒xAI今天注意到,备受关注的全球顶级域名 AI.com 跳转目标近日发生变更。目前访问 AI.com 会跳转至一个全新的、充满神秘感的网站。此前该域名曾指向人工智能初创公司 DeepSeek 的相关页面,但根据最新观察,AI.com 现已解绑 DeepSeek。
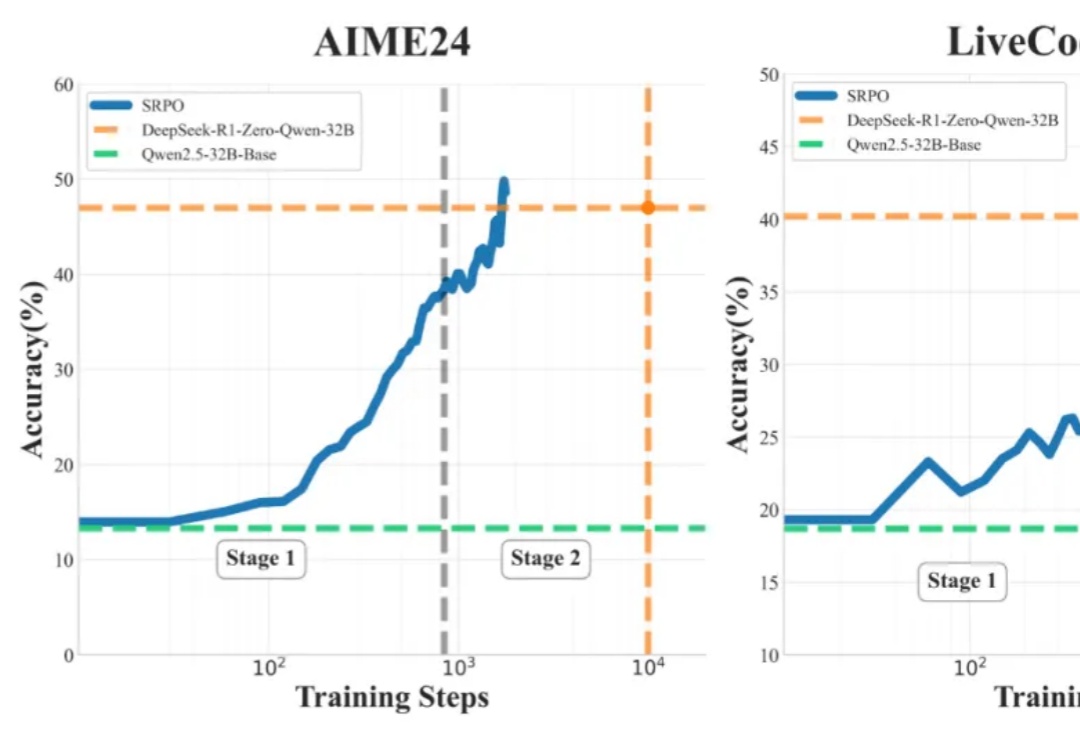
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

Transformer作者Ashish Vaswani团队重磅LLM研究!简单指令:「Wait,」就能有效激发LLM显式反思,表现堪比直接告知模型存在错误。

最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。

2025开年伊始,从1月DeepSeek R1发布引发新一轮国产大模型技术爆发,到3月Manus横空出世启动内测打开AI智能体话题热度,从底层基础设施到终端产品应用,从产业深耕提升纵深能力到产品创新形成差异化竞争优势,无论是技术能力还是商业模式,国产AI都处于全球领先水平。海外无论是政策环境还是供需关系,均从内外部双轮驱动国产AI出海蓄势待发。

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。