详细解读DeepSeek新年的第一篇论文,他们就是这个时代的源神。
详细解读DeepSeek新年的第一篇论文,他们就是这个时代的源神。2026年新年第一天,DeepSeek又开卷了。
来自主题: AI资讯
9478 点击 2026-01-04 12:20
 搜索
搜索
2026年新年第一天,DeepSeek又开卷了。
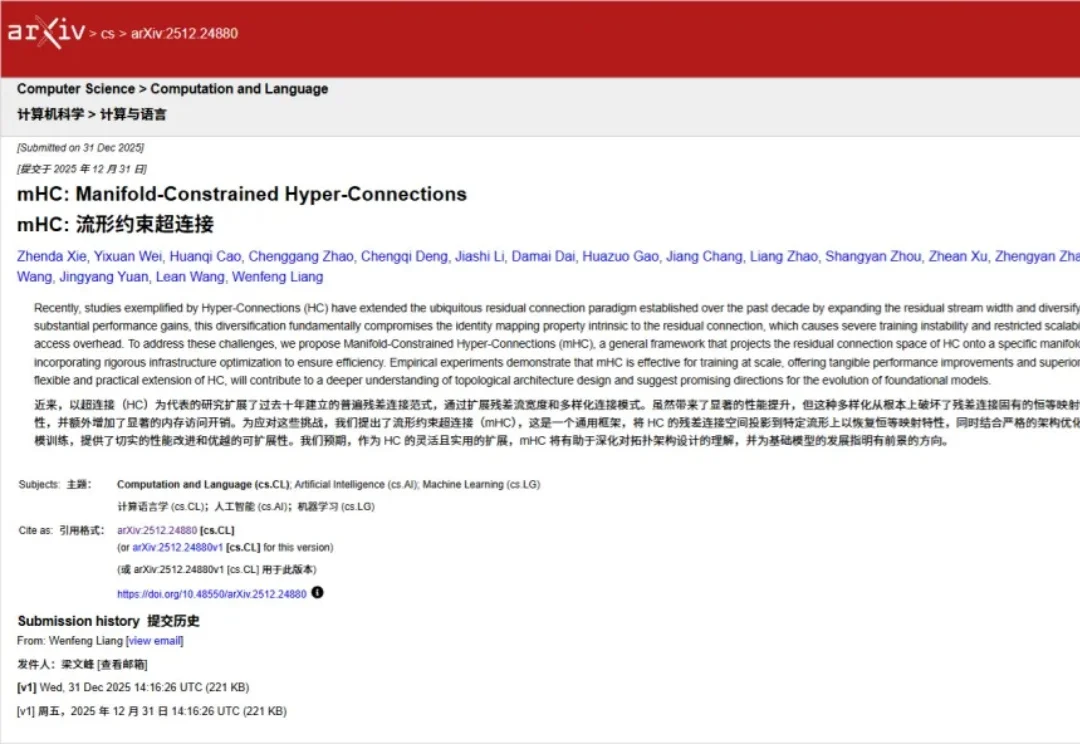
2026年新年第一天,DeepSeek上传新论文。给何恺明2016成名作ResNet中提出的深度学习基础组件“残差连接”来了一场新时代的升级。残差连接自2016年ResNet问世以来,一直是深度学习架构的基石。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

最近,APPSO 终于拿到了这台来自黄仁勋倾情推荐的个人超算,英伟达 DGX Spark;到手的第一感觉,就是「小而美」。这电脑也太小了,没有 Mac Studio 那般笨重,可能就和 Mac Mini 差不多大;然后是银色的亮和用来散热的金属丝网又让它有点不一样,是专属的硬核美感。

你知道吗,DeepSeekTwitter、Mac、Qwen,最初都只是副项目?真正改变世界的产品,可能根本不在公司的PPT路线图上。
现在生成一个视频,比你刷视频还要快。
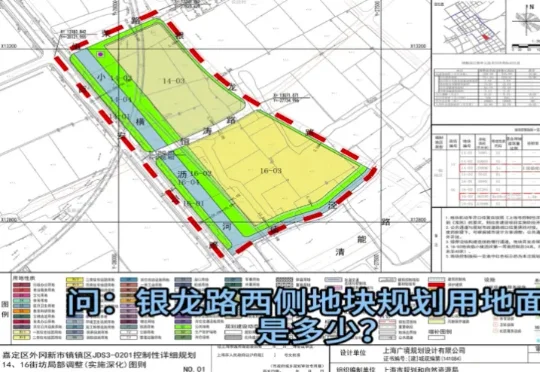
近日,由上海市规划资源局与商汤大装置联合打造的全国规划资源领域首个基础大模型“云宇星空大模型”(专业版)上线。这并非一个简单的对话机器人,而是一个6000亿参数、深度嵌入规资全业务系统的行业大模型:它能调取地图、做统计,能理解规划图纸、会写报告,覆盖从知识检索、空间分析到决策支撑的完整工作闭环。

刚刚,由SciMaster团队推出的AI机器学习专家ML-Master 2.0,基于国产开源大模型DeepSeek,在OpenAI权威基准测试MLE-bench中一举击败Google、Meta、微软等国际顶流,刷新全球SOTA,再次登顶!目前该功能已在SciMaster线上平台开放waiting list,欢迎申请体验。

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!