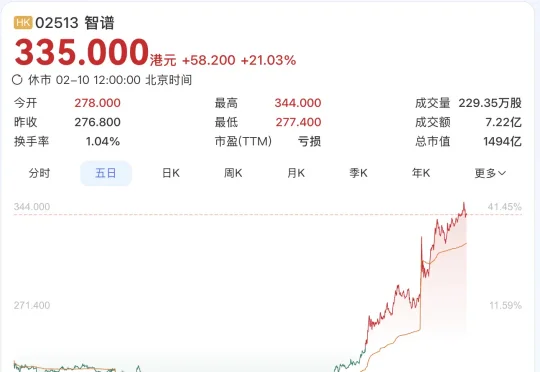
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
来自主题: AI资讯
9852 点击 2026-02-10 16:27
 搜索
搜索
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
“DeepSeek-V3是在Mistral提出的架构上构建的。”

面对《the Big Technology Podcast》抛出的问题,Mistral AI的 CEO Arthur Mensch 表示:大模型肯定会走向商品化,当模型表现越来越接近,那么竞争就不在于模型本身,而在于如何让客户用起来。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。
今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。

DeepSeek 一发布模型,总会引起业内的高度关注与广泛讨论,但也不可避免的暴露出一些小 Bug。
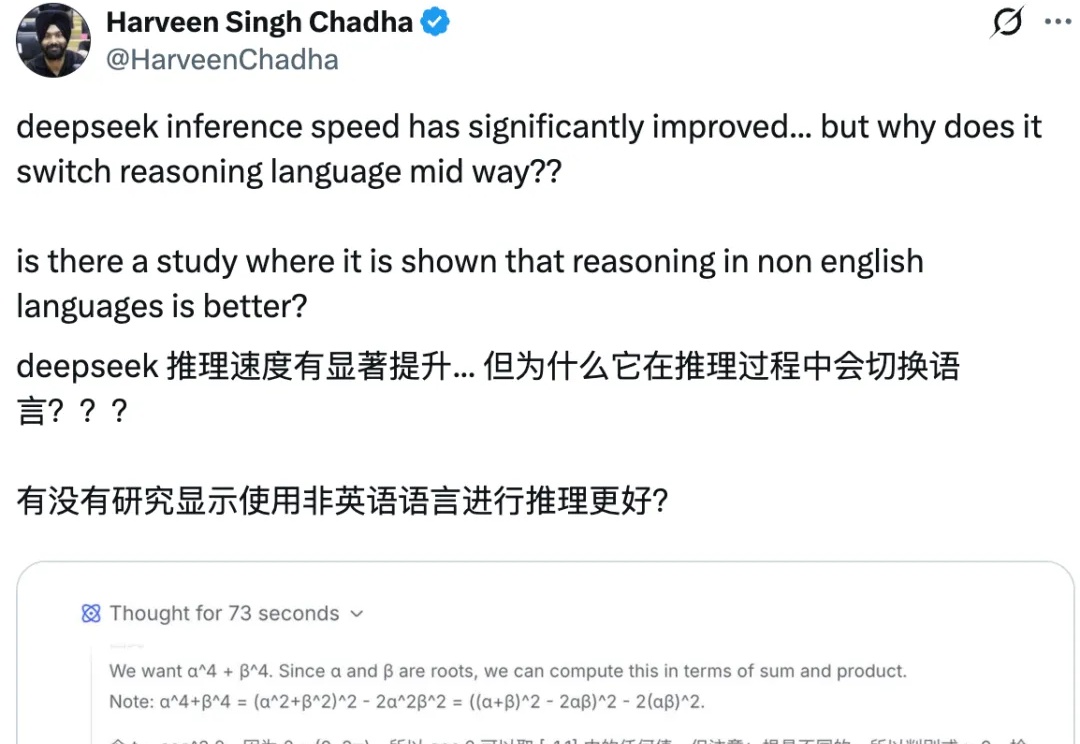
就在前天,DeepSeek 一口气上新了两个新模型,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。

DeepSeek-V3.2很强很火爆,但随着讨论的深入,还是有bug被发现了。 并且是个老问题:浪费token。不少网友都提到,DeepSeek-V3.2的长思考增强版Speciale,确确实实以开源之姿又给闭源TOP们上了压力,但问题也很明显: