
数据难清洗?试试ThinkJSON奖励算法,让DeepSeek-R1驱动Multi-Agent实现
数据难清洗?试试ThinkJSON奖励算法,让DeepSeek-R1驱动Multi-Agent实现在实际应用中,我们常常需要模型输出具有严格结构的数据,比如生物制药生产记录、金融交易报告或医疗健康档案等。这种结构化输出的需求在生物制造、金融服务、医疗健康等严格监管的领域尤为重要。
来自主题: AI技术研报
5411 点击 2025-02-27 10:25
 搜索
搜索
在实际应用中,我们常常需要模型输出具有严格结构的数据,比如生物制药生产记录、金融交易报告或医疗健康档案等。这种结构化输出的需求在生物制造、金融服务、医疗健康等严格监管的领域尤为重要。

即日起,北京时间每日00:30-08:30为错峰时段,API 调用价格大幅下调:DeepSeek-V3 降至原价的50%,DeepSeek-R1降至25%,在该时段调用享受更经济更流畅的服务体验。具体价格参看图2.
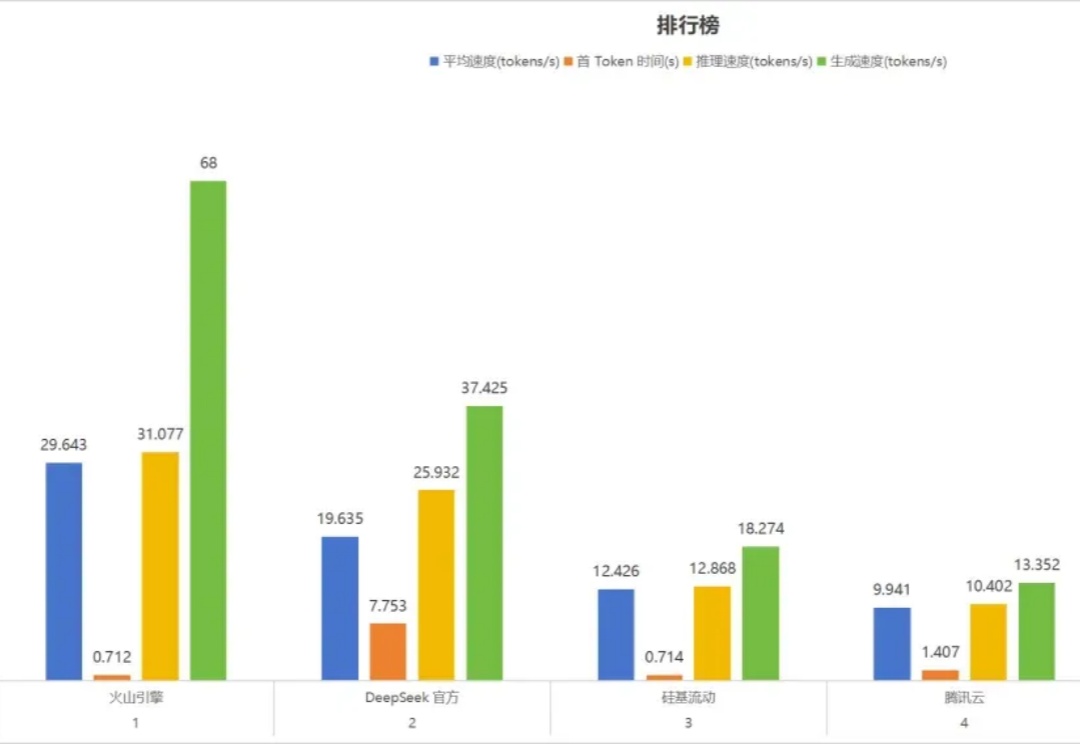
部署 DeepSeek 系列模型,尤其是推理模型 DeepSeek-R1,已经成为一股不可忽视的潮流。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。

推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。
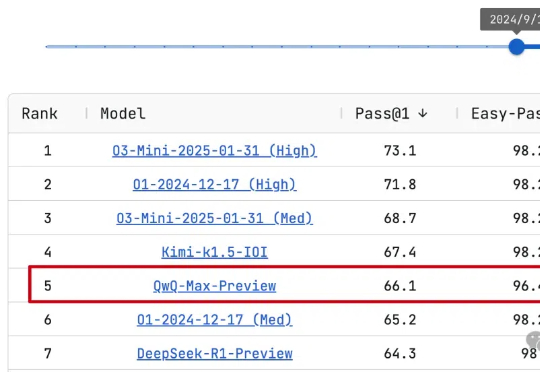
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
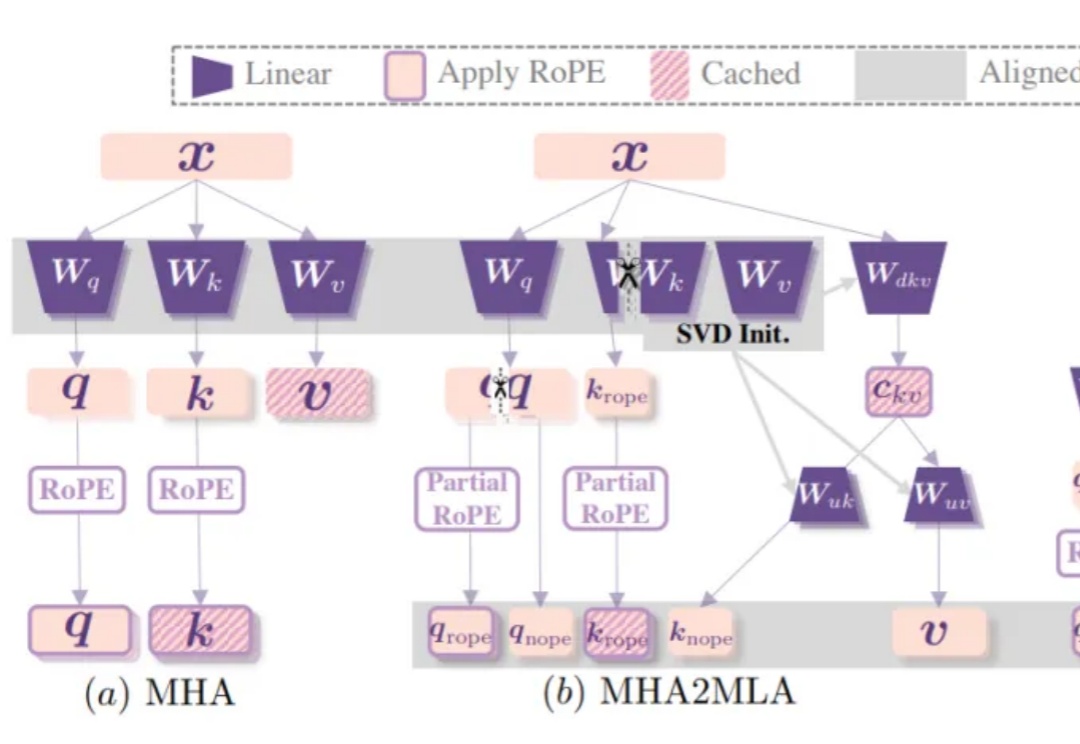
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!
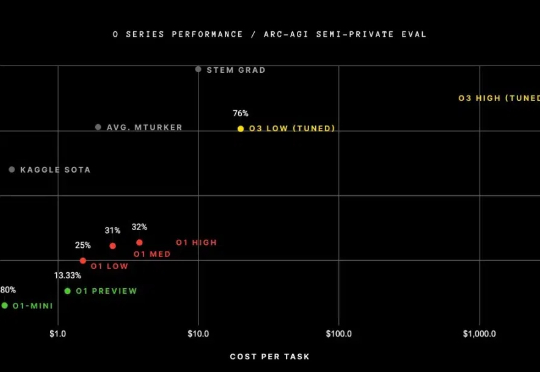
自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。
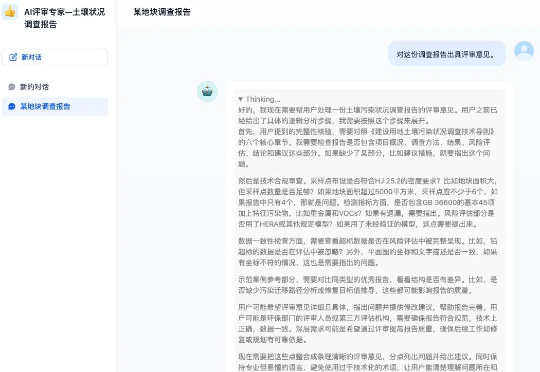
国内首个生态环境“AI报告评审专家”已完成土壤污染状况调查报告领域的前期训练,启动上线试运行。日前,无锡市梁溪生态环境局已完成DeepSeek-R1“满血版”大模型本地化部署,通过AI与生态环境业务深度融合,
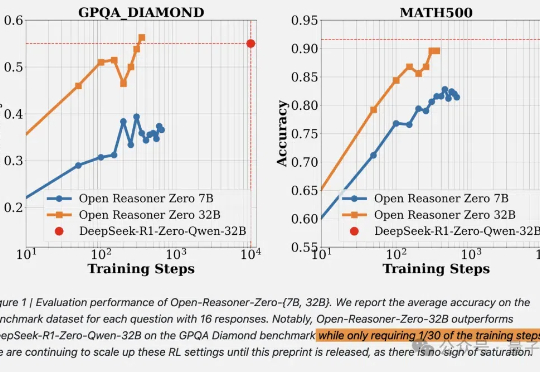
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。