阿里千问QwQ-32B推理模型开源,比肩671B满血DeepSeek-R1!笔记本就能跑
阿里千问QwQ-32B推理模型开源,比肩671B满血DeepSeek-R1!笔记本就能跑仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
来自主题: AI技术研报
7571 点击 2025-03-07 10:28
 搜索
搜索
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
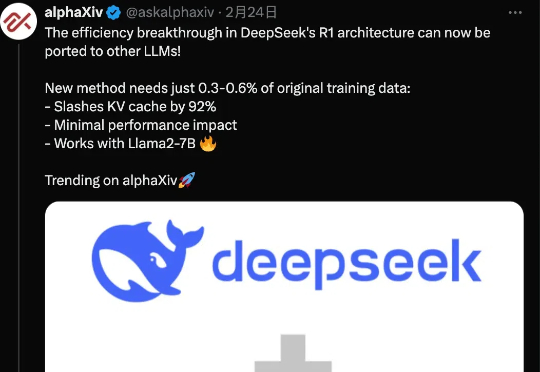
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
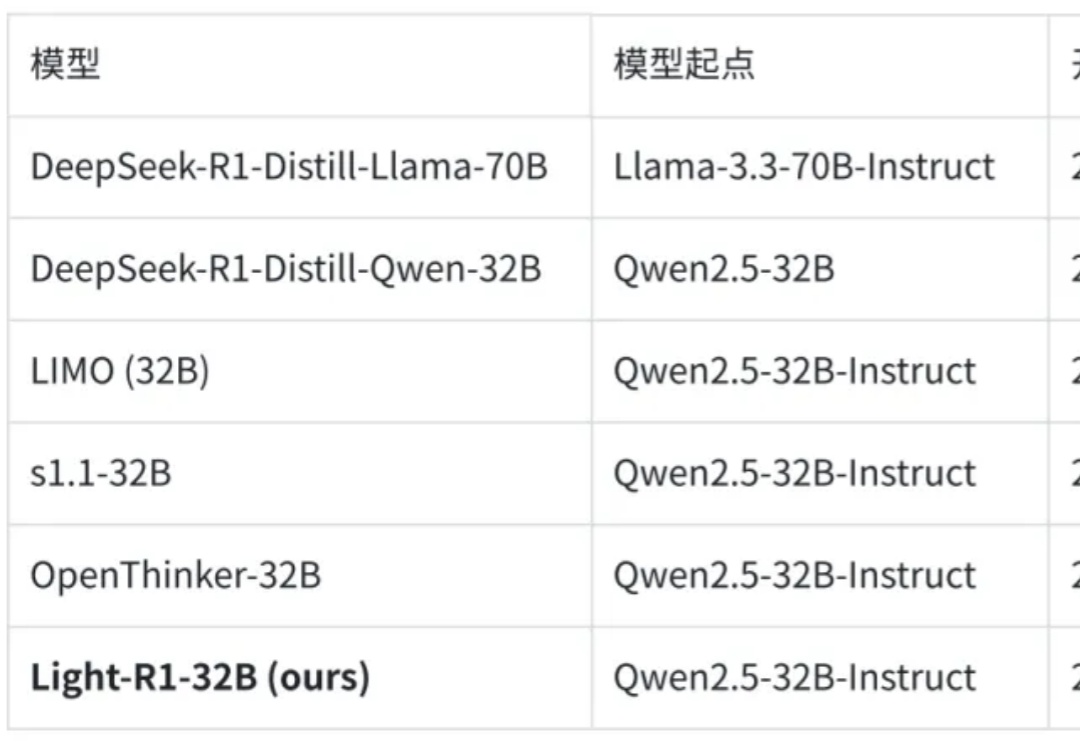
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

又一个「DeepSeek 王炸组合」,来了。2 月 28 日,两个国民级应用,百度文库和百度网盘,全量接入了 DeepSeek-R1 满血版。
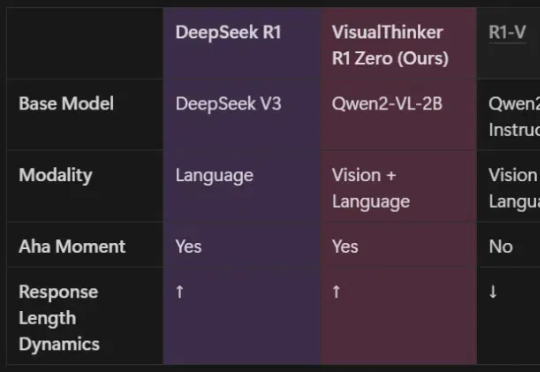
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!
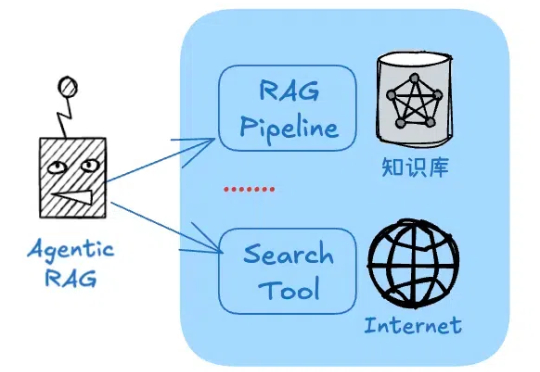
RAG是一种基于“检索结果”做推理的应用,这大大限制了类似DeepSeek-R1模型的发挥空间。但又的确存在将RAG的准确性与DeepSeek深度思考能力结合的场景,而不仅仅是回答事实性问题。比如:
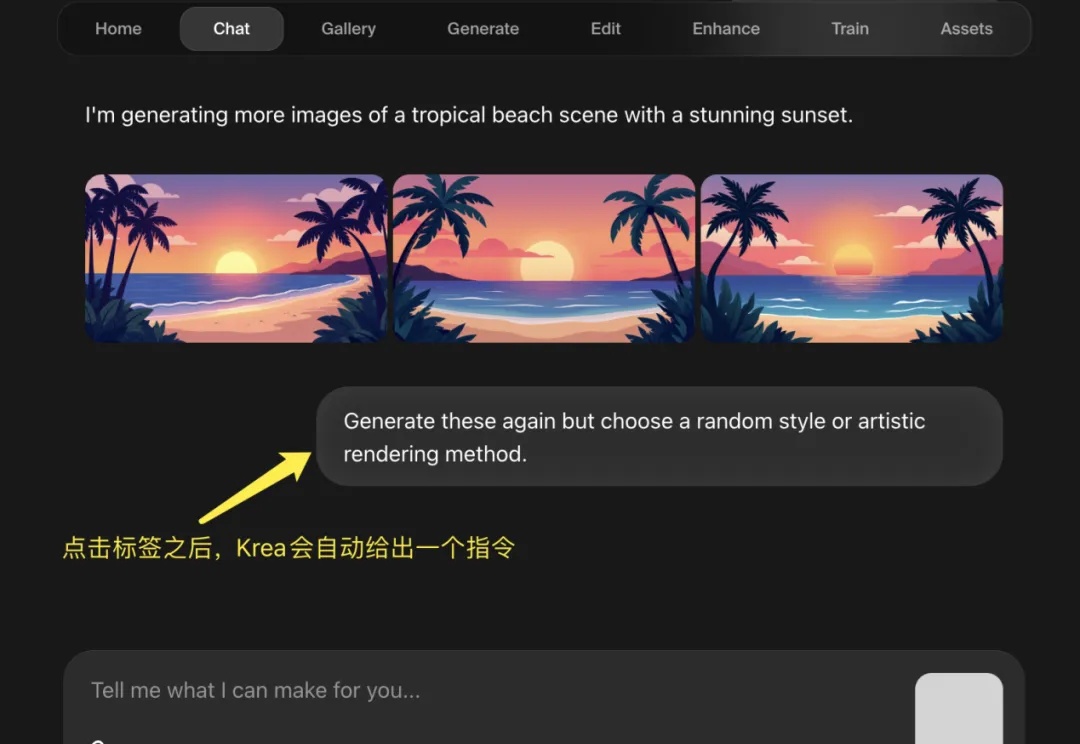
在 R1 推理模型大火之后,全民接力集成 DeepSeek,有硅基流动这样的大模型云服务平台、有腾讯元宝这样的 Chatbot,甚至微信这样的顶流。但是,AI 图片类产品却鲜少有接入 DeepSeek R1 的新闻,而从 DeepSeek-R1 发布到 Krea 宣布上线新功能仅仅 10 天,这个反应应该是图像产品中最快的。
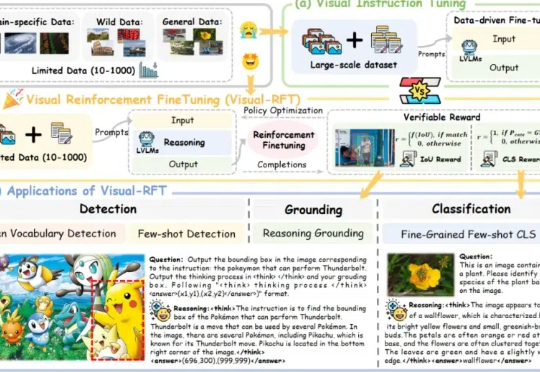
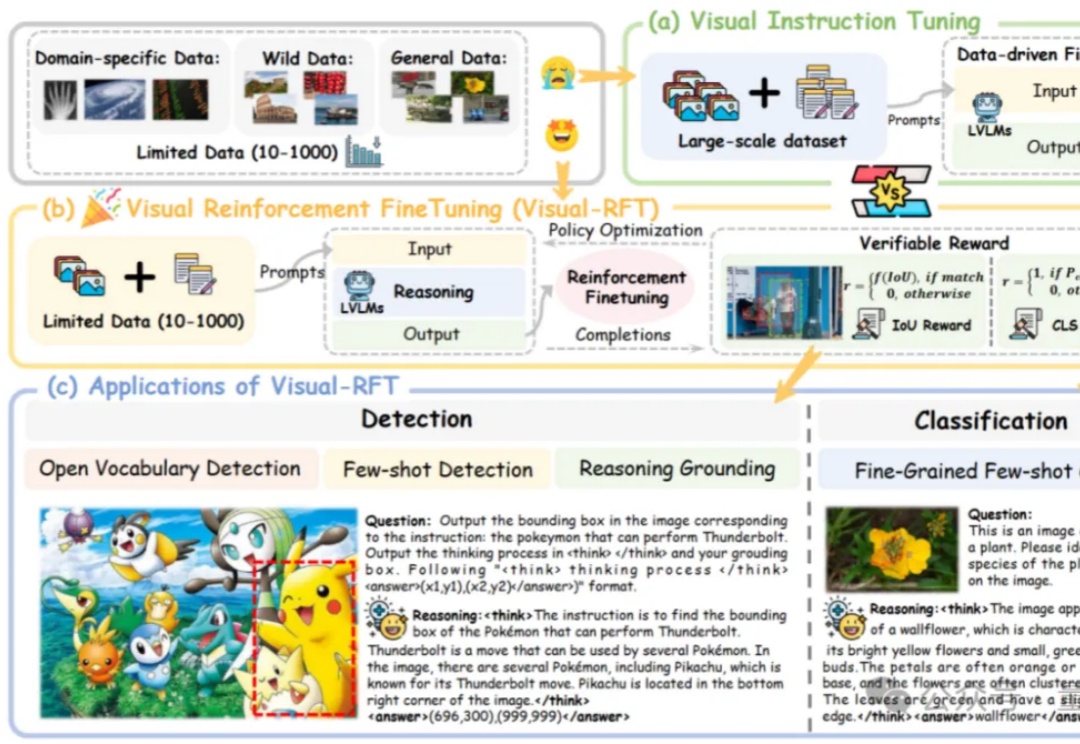
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!
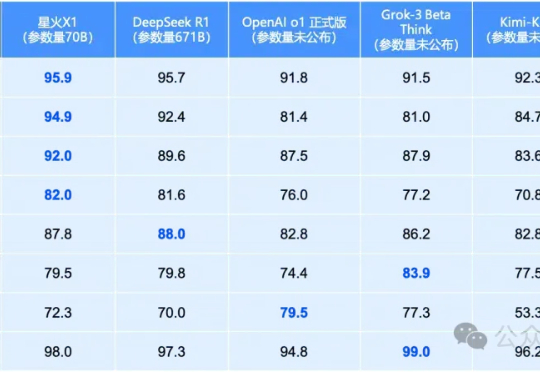
就在昨天,全国产算力训出的讯飞星火X1全面升级!70B小身板在数学领域全面领先,性能直接对标OpenAI o1和DeepSeek-R1。单机部署成本骤降,彻底颠覆行业应用门槛。