
视频生成1.3B碾压14B、图像生成直逼GPT-4o!港科&快手开源测试时扩展新范式
视频生成1.3B碾压14B、图像生成直逼GPT-4o!港科&快手开源测试时扩展新范式测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
来自主题: AI技术研报
8891 点击 2025-06-10 16:18
 搜索
搜索
测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
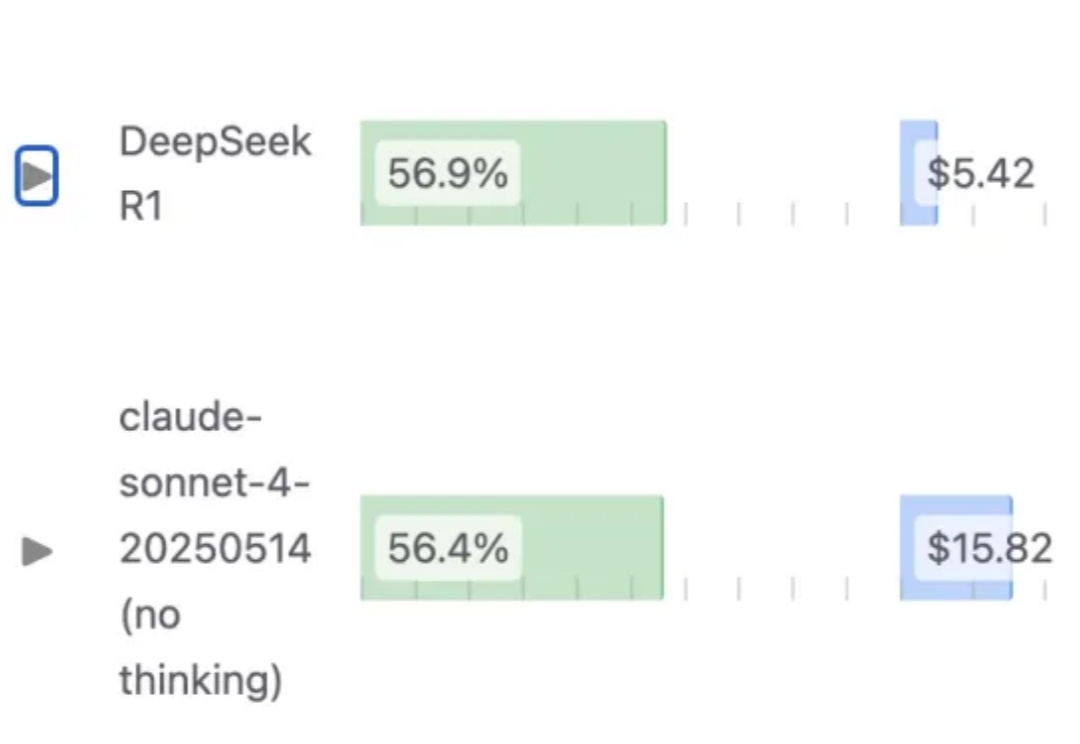
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?

虎嗅从多个独立信源获悉,半年前,某DeepSeek核心高管已悄然离职创业,并将于2025年圣诞节前后发布Agent产品。有信源告诉虎嗅,该高管系原DeepSeek CTO。
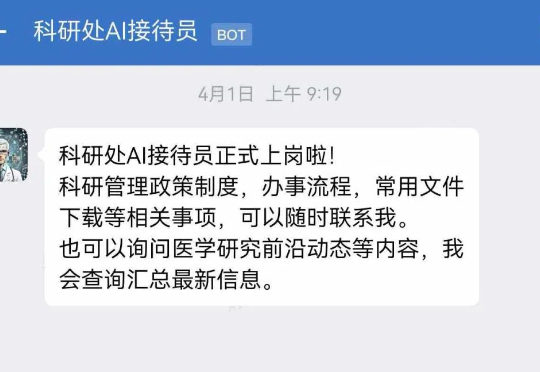
AI大模型正在医疗服务行业中扎根。 “我们医院在科研平台上已经接入使用了DeepSeek。”北京某三甲医院相关负责人对光锥智能说道,“形式类似于AI助理,能提供科研政策问答、查询、常用文件下载等功能。”
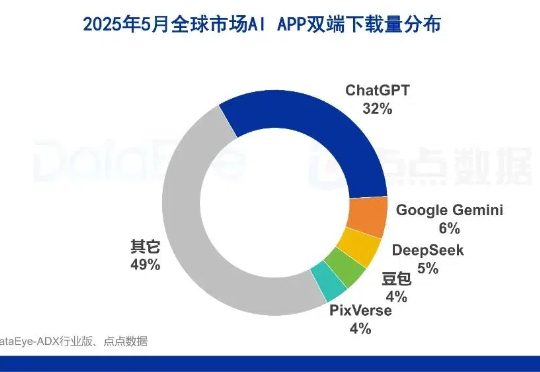
5月份,AI应用市场格局再度出现变化,夸克登顶买量素材榜首,腾讯元宝买量、下载量双双大跌,DeepSeek下载量进一步下滑。

Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。

AI会有情感吗?机器人会不会感知到疼痛?未来人类与AI的边界在哪里?我们梳理了"互联网女皇"玛丽·米克尔、"AI教父"杰弗里·辛顿、科技预言家凯文·凯利、DeepMind CEO德米斯·哈萨比斯的近期访谈,他们从诸多维度,各自表达他们心中的AI时代图景。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

如果细究DeepSeek开源席卷的行业巨变,云厂商无疑是最适合讲述AI故事的主角。几个月过去,分析师们迫切地想检验这场新变革的成果,纷纷在5月各家大厂召开的财报电话会议上追问进展。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。