
老黄开年演讲「含华量」爆表!直接拿DeepSeek、Kimi验货下一代芯片
老黄开年演讲「含华量」爆表!直接拿DeepSeek、Kimi验货下一代芯片CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。
来自主题: AI资讯
6980 点击 2026-01-07 09:33
 搜索
搜索
CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
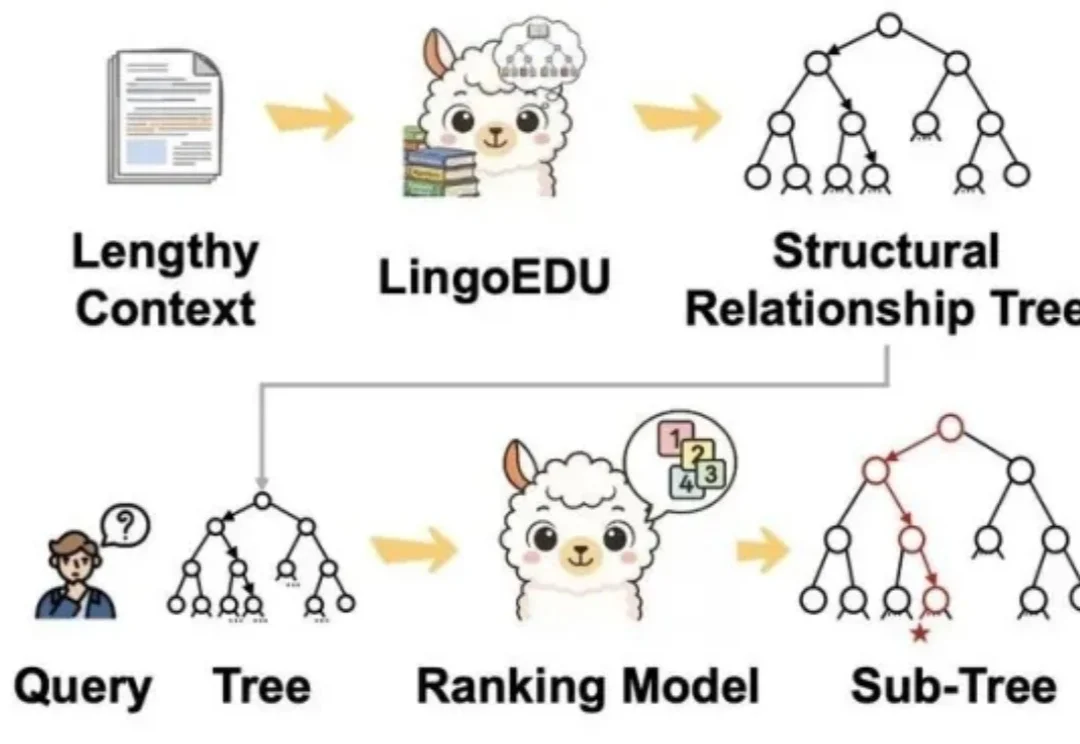
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!
2026年新年第一天,DeepSeek又开卷了。
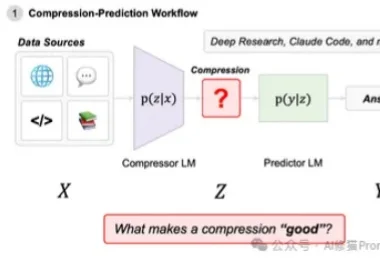
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
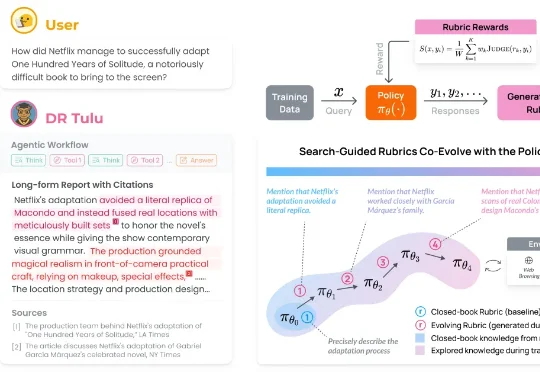
近日,美国华盛顿大学博士生邵如琳和合作团队打造出一个名为 Deep Research Tulu(DR Tulu)的深度研究小助手。使用一次 OpenAI 的 Deep Research 服务可能需要大约 1.8 美元,而 DR Tulu 使用一次的成本却不到 0.002 美元,这几乎是千倍的效率提升,这意味着未来个人或者小团队也能负担得起高质量、高可信度的 AI 研究服务。

近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期
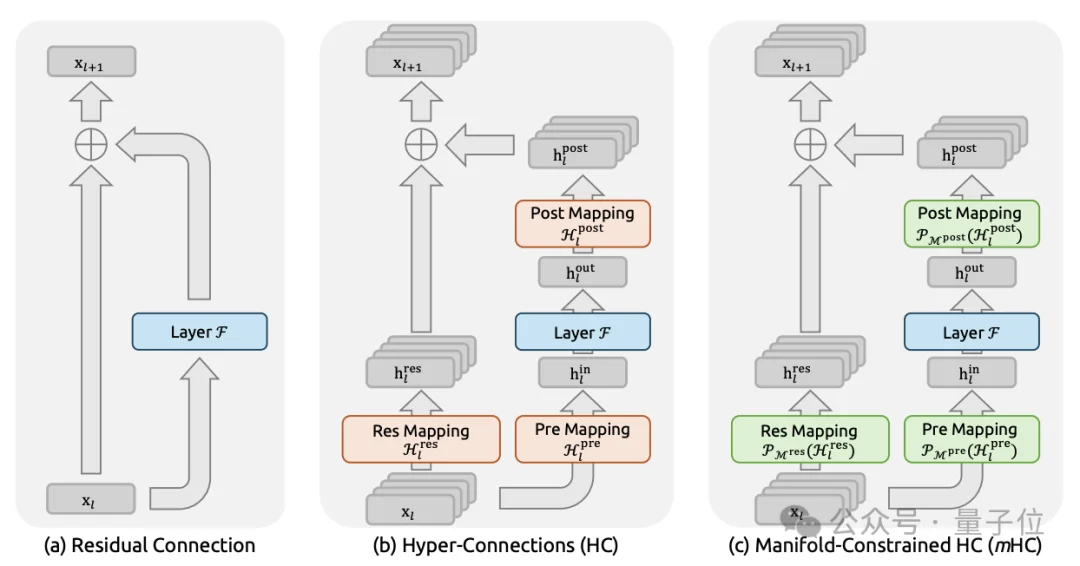
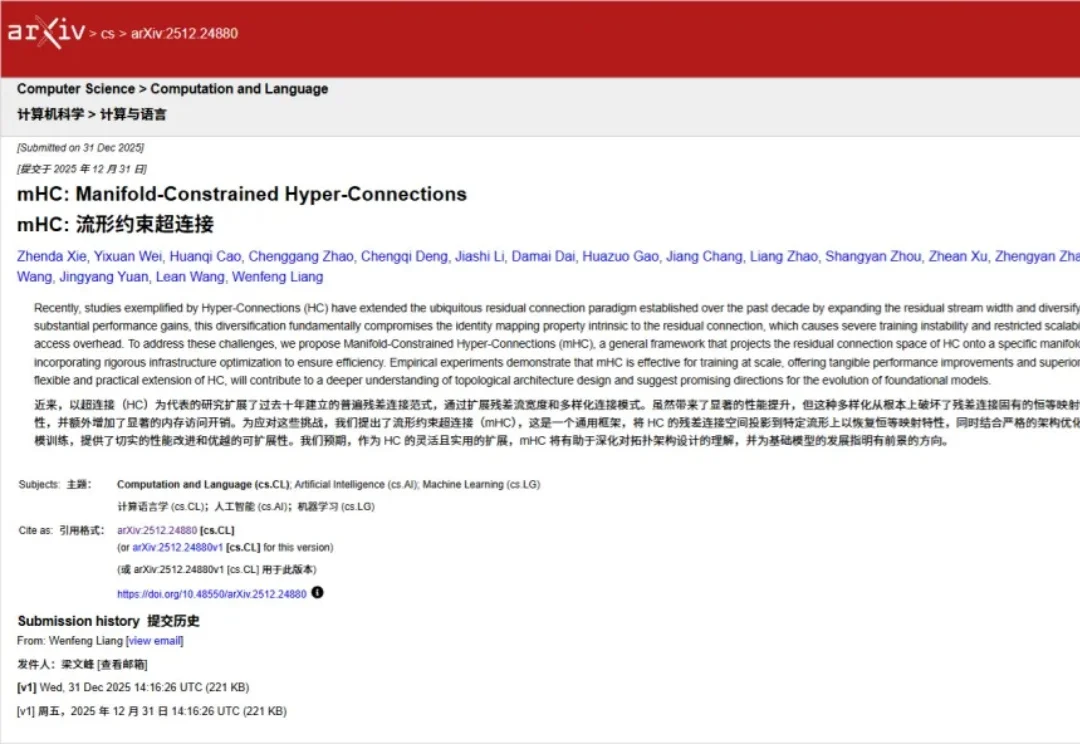
2026年新年第一天,DeepSeek上传新论文。给何恺明2016成名作ResNet中提出的深度学习基础组件“残差连接”来了一场新时代的升级。残差连接自2016年ResNet问世以来,一直是深度学习架构的基石。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

2026年,Scaling Law是否还能继续玩下去?对于这个问题,一篇来自DeepMind华人研究员的万字长文在社交网络火了:Scaling Law没死!算力依然就是正义,AGI才刚刚上路。