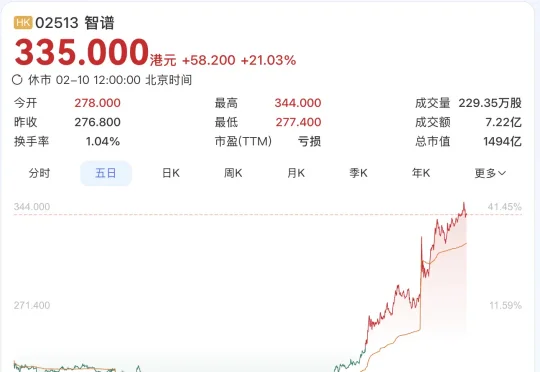
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力
GLM-5架构曝光,智谱两日涨60%:采用DeepSeek同款稀疏注意力不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
来自主题: AI资讯
9871 点击 2026-02-10 16:27
 搜索
搜索
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
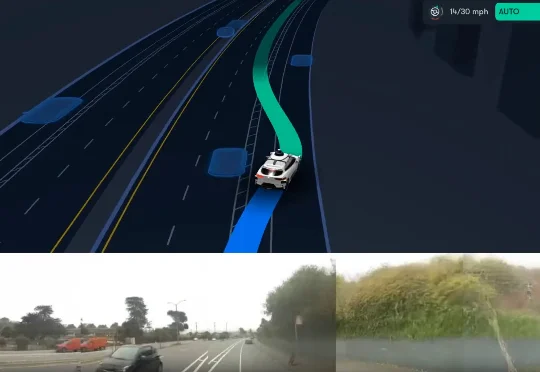
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
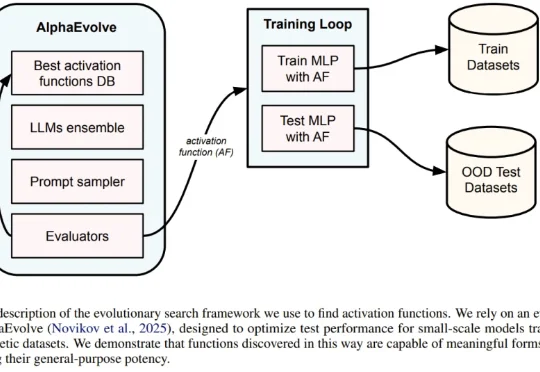
一直以来,神经网络的激活函数就像是 AI 引擎中的火花塞。从早期的 Sigmoid、Tanh,到后来统治业界的 ReLU,再到近年来的 GELU 和 Swish,每一次激活函数的演进都伴随着模型性能的提升。但长期以来,寻找最佳激活函数往往依赖于人类直觉或有限的搜索空间。

过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
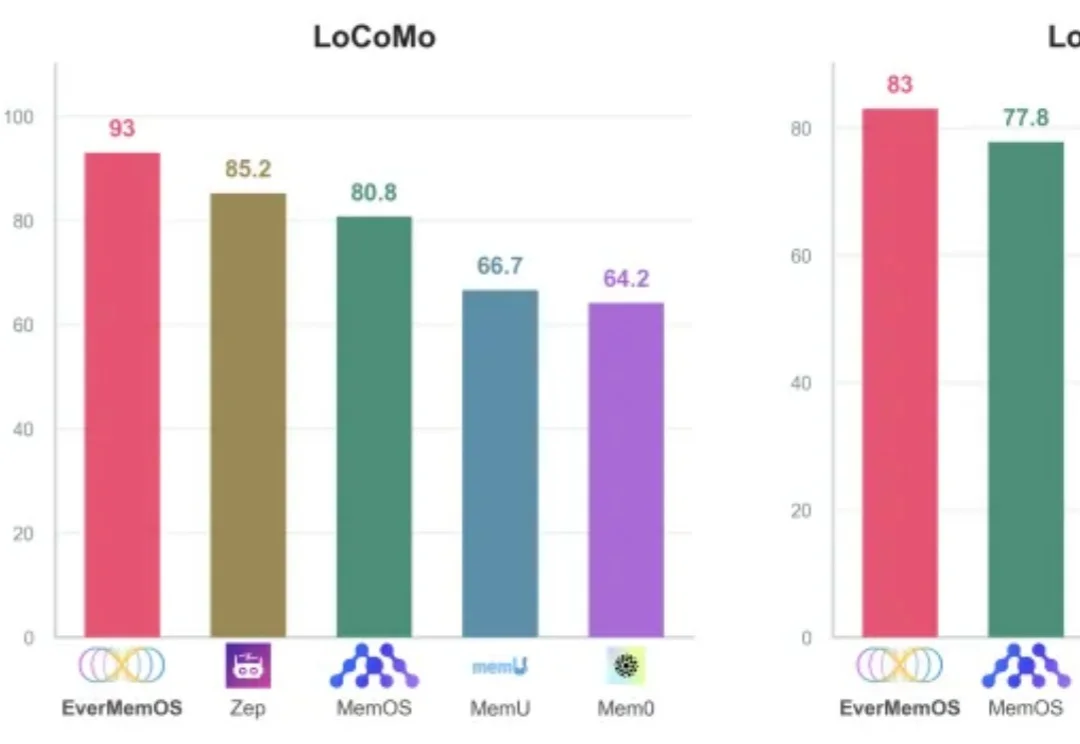
开年,DeepSeek论文火遍全网,内容聚焦大模型记忆。
就在刚刚,据《南华早报》援引知情人士最新消息,智谱 AI 计划在未来两周内,也就是春节前发布其新旗舰模型 GLM-5。与此同时,MiniMax 也预计将于春节前发布 M2.2 模型,这是在原有 M2.1 基础上进行的小幅更新,重点提升编程能力。

语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。
