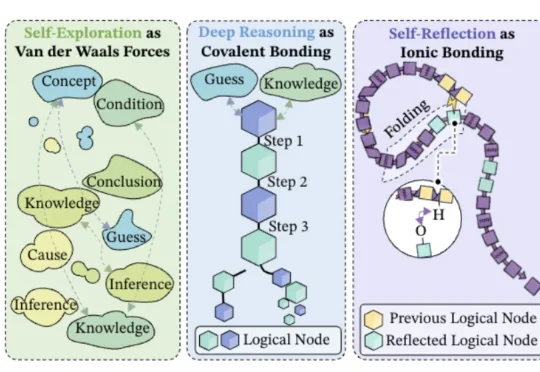
字节Seed用化学思想搞AI,把DeepSeek-R1的脑回路拆成了分子结构
字节Seed用化学思想搞AI,把DeepSeek-R1的脑回路拆成了分子结构字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!
来自主题: AI技术研报
10273 点击 2026-02-24 15:37
 搜索
搜索
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!

刚刚, Anthropic 发推称,DeepSeek、Moonshot AI和MiniMax三家国内的 AI 公司对Claude进行大规模的蒸馏攻击。OK, A 社你真的很讨厌中国公司了。简单说就是:这三家公司用大量假账号,疯狂地向 Claude 提问,然后拿 Claude 的回答去训练自己的模型。

今天早上,Google Labs发布了Pomelli最新功能Photoshoot,我们可以从一张产品图片出发,轻松制作高质量定制品牌照片,用于产品营销。Pomelli是Google Labs联合Google DeepMind于2025 年10月推出的AI营销工具实验项目,底层驱动模型为Nano Banana,专为中小企业设计。

作者 | 高允毅 很多人知道,Transformer 是谷歌发明的。但 ChatGPT,却不是谷歌做出来的。这件事,在过去几年,几乎成了硅谷最大的“遗憾注脚”。 但如果真正走进今天的 Google D

当地时间 2 月 19 日,Google 曝光 Gemini 3.1 Pro 最新模型。在 ARC-AGI-2 这个公认的推理基准测试中,Gemini 3.1 Pro 拿到了 77.1% 的分数。什么概念?它的前辈 Gemini 3 Pro 只有 31.1%,就连专门用来「深度思考」的 Gemini 3 Deep Think 也只有 45.1%。

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在
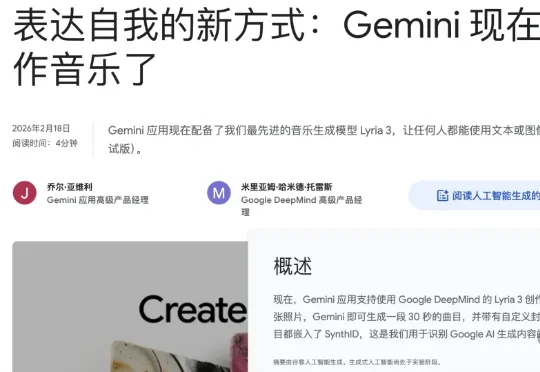
谷歌在 7.5 亿月活的 Gemini 中上线了 AI 音乐生成功能,输入一句话或一张照片,几秒就能得到一首带人声和歌词的完整歌曲。背后是 DeepMind 最新的 Lyria 3 模型,训练数据超 200 万首曲目。对 Suno 等 AI 音乐创业公司而言,竞争从此不再只是比模型,更是要比入口。

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从
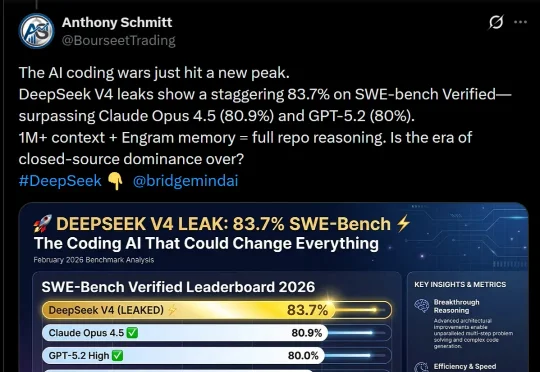
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
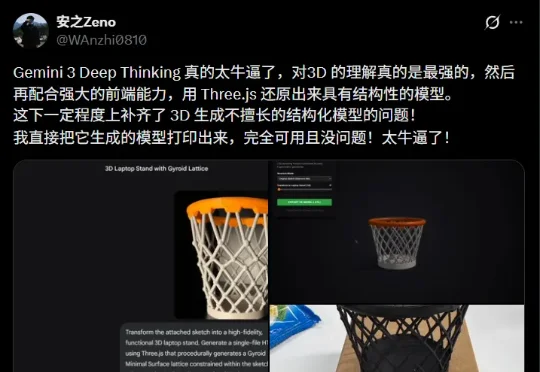
现在, Gemini 3 Deep Think 看一眼照片,就能脑补全这张锅在各个角度的长宽高、厚度甚至把手的弧度,直接变出一个立体实物原型。