
欧盟宣布豪掷 1.5 万亿追赶中美 AI ,巴黎峰会还有这些值得关注的新观点
欧盟宣布豪掷 1.5 万亿追赶中美 AI ,巴黎峰会还有这些值得关注的新观点席卷全球的 DeepSeek 依然是科技圈最大的话题,连 San Altman 都承认每天醒来都会担忧。因此本周在巴黎举办的 AI 行动峰会聚光灯稍显黯淡,但这里依然汇聚了全球大量重要的头脑。
来自主题: AI资讯
10168 点击 2025-02-12 21:21
 搜索
搜索
席卷全球的 DeepSeek 依然是科技圈最大的话题,连 San Altman 都承认每天醒来都会担忧。因此本周在巴黎举办的 AI 行动峰会聚光灯稍显黯淡,但这里依然汇聚了全球大量重要的头脑。
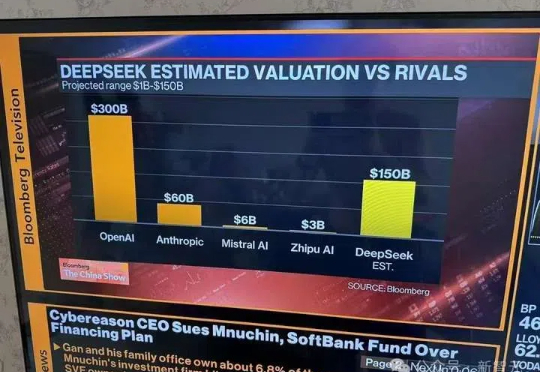
最近,外媒Bloomberg曝出了惊人消息:DeepSeek的估值竟已飙至1500亿美元,已经达到OpenAI的一半?在巴黎AI峰会现场,DeepSeek已经如同房间里的大象。甚至巴黎地铁里的70岁老人也开始讨论DeepSeek!
最近有文章称“DeepSeek让多地智算中心停建”,但不少业内人士并不认同。春节之后,不少企业,尤其是上市公司,都正在接入DeepSeek。未来几个月将是应用验证期。

最近,全球科技行业的焦点无疑落在了DeepSeek引发的热潮之上。几乎在一夜之间,全球市场对中国AI大模型及其相关产业的态度发生了180度转变——从此前的“过度悲观”瞬间跳跃至“极度乐观”,2025也似乎成为中美AI对决元年。

DeepSeek 最近的爆火程度令人咋舌。短短20天内用户量就突破3000万,导致官方服务器几乎天天处于过载状态。虽然市面上已经涌现出不少第三方接入平台,但这些平台大多针对个人用户,对开发者和企业的需求难以满足。
凌晨的时候,使用deepseek深度思考+联网搜索做了一个AI产品卡片,展示效果很惊艳,如下是做了几个关于AI教育智能硬件产品的特性图,放几个看看效果。我们需要深度思考+联网搜索的能力,需要根据关键词去检索到详细的信息源,因此联网搜索必不可少,然后根据如上搜索整合的信息让deepseek自适应地根据内容进行排版,选择不同地风格,呈现不同地样式。
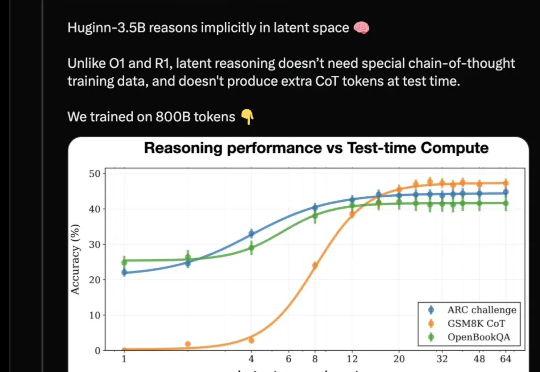
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

这一篇文章来源于我自己的困惑而进行的探索和思考,再进行多次讨论后总觉隔靴搔痒,理解不透彻。 而在我自己整理后,发现已经有小伙伴点明了他们的区别。但是因为了解深度的不够,即使告诉了答案,我也无法理解,总有隔靴搔痒之感。
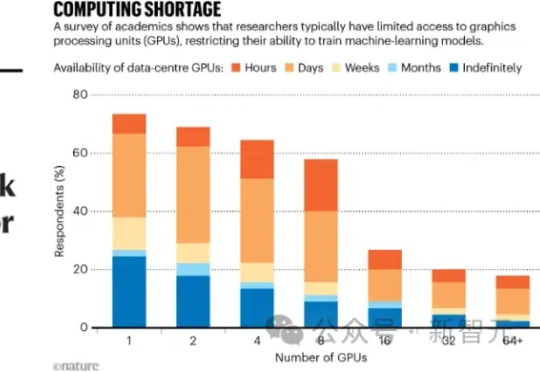
梁文峰说,钱从来都不是问题,唯一担心的是缺算力。不过,基于国产昇腾算力的DeepSeek R1系列推理API,性能已经直接对标高端GPU了!而且,华为已经率先携手国内15所头部高校,打造出了独一份的科教创新卓越/孵化中心,通过产教融合、科教融汇破解高校科研的算力困局。

DeepSeek的爆火,让AI大模型在新一年的开年,又一次引起了全球的关注。然而,时至今日全球AI领域还没有完全消化DeepSeek带来的实质影响——这样的模式将给全球、给中国AI领域带来什么样的变局?