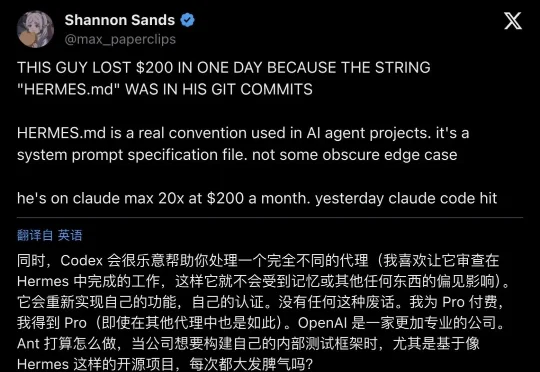
开发者让 Codex「审」另一个 AI agent 写的代码,近万人围观:别让同一个大脑既当裁判又当运动员!
开发者让 Codex「审」另一个 AI agent 写的代码,近万人围观:别让同一个大脑既当裁判又当运动员!一个开发者公开了自己的工作流:让 OpenAI Codex 专门去审查 Hermes agent 写出来的代码,理由只有一个——审稿人不能和写稿人共享同一套记忆。这条推文引发了近万次浏览,背后藏着一个 agent 工程化的新趋势:多模型协作的价值,可能在于互相制衡。
来自主题: AI资讯
6919 点击 2026-04-28 13:15