CVPR 2025:单图秒变专业影棚,几何/材质/光影全搞定,数据训练代码全开源
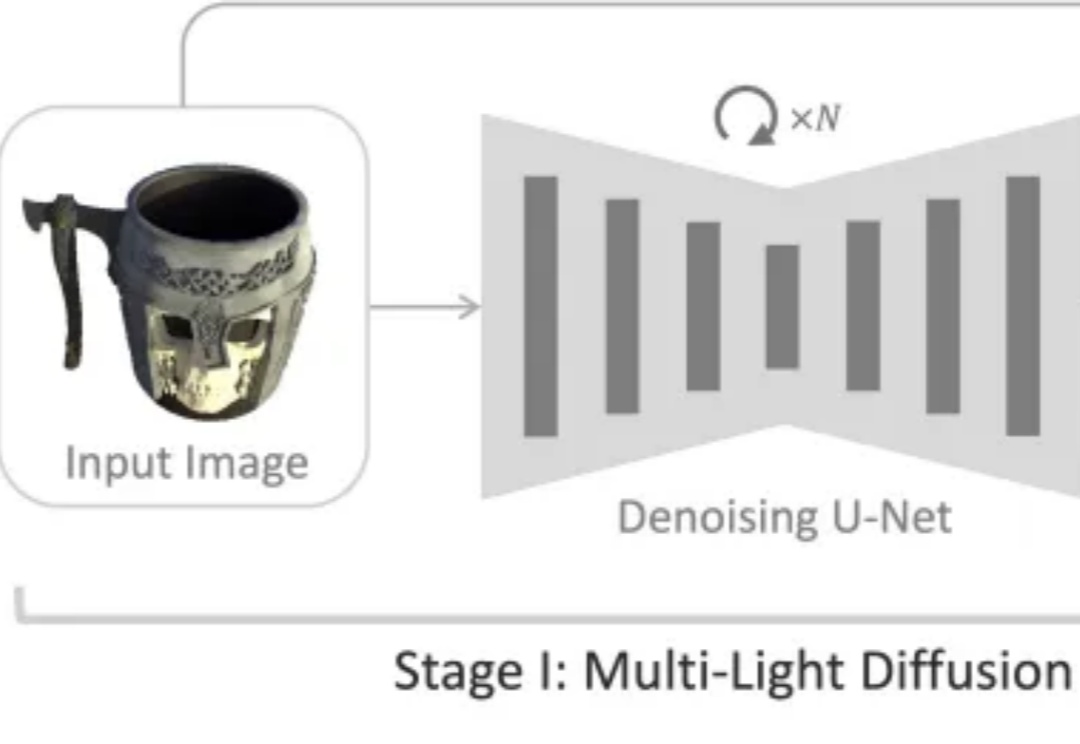
CVPR 2025:单图秒变专业影棚,几何/材质/光影全搞定,数据训练代码全开源如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。
来自主题: AI技术研报
4344 点击 2025-04-03 10:11
 搜索
搜索
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。

当你翻开相册,看到一张平淡无奇的风景照,是否希望它能更温暖、更浪漫,甚至更忧郁?现在,EmoEdit 让这一切成为可能 —— 只需输入一个简单的情感词,EmoEdit 便能巧妙调整画面,使观众感知你想传递的情感。

三维高斯泼溅(3D Gaussian Splatting, 3DGS)技术基于高斯分布的概率模型叠加来表征场景,但其重建结果在几何和纹理边界处往往存在模糊问题。
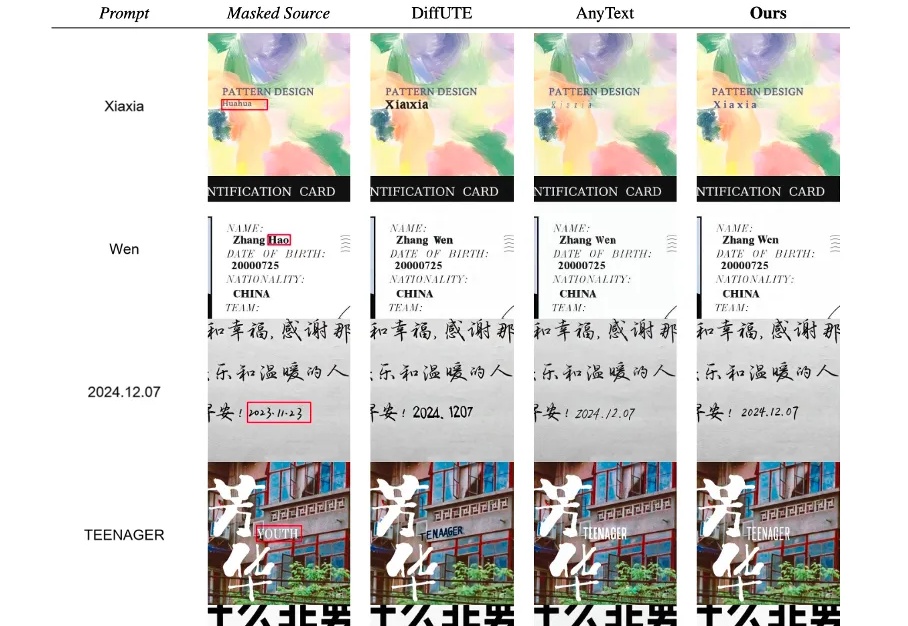
图像编辑大礼包!美图5篇技术论文入围CVPR 2025。

3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
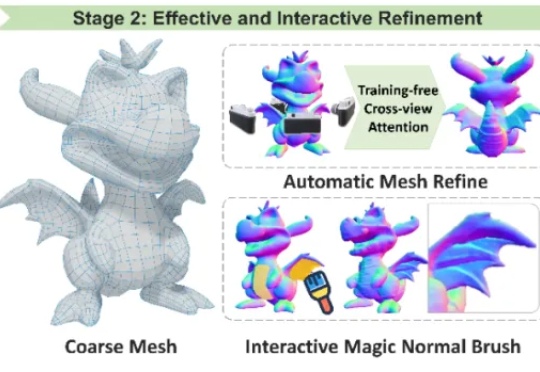
香港科技大学谭平教授团队在 CVPR 2025 发表两项三维生成技术框架,核心代码全部开源,助力三维生成技术的开放与进步。其中 Craftman3D 获得三个评委一致满分,并被全球多家知名企业如全球最大的多人在线游戏创作平台 Roblox, 腾讯混元 Hunyuan3D-2,XR 实验室的 XR-3DGen 和海外初创公司 CSM 的 3D 创作平台等重量级项目的引用与认可。

在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。
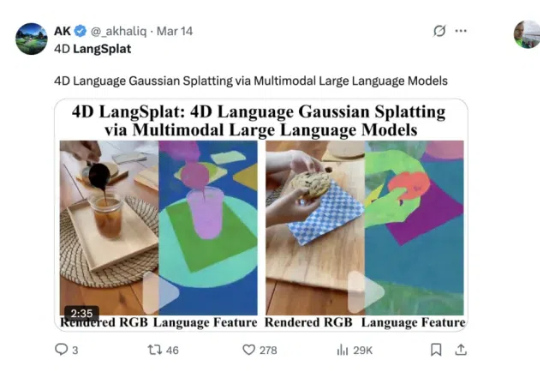
来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法——4D LangSplat。该方法基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。

任意一张立绘,就可以生成可拆分3D角色!