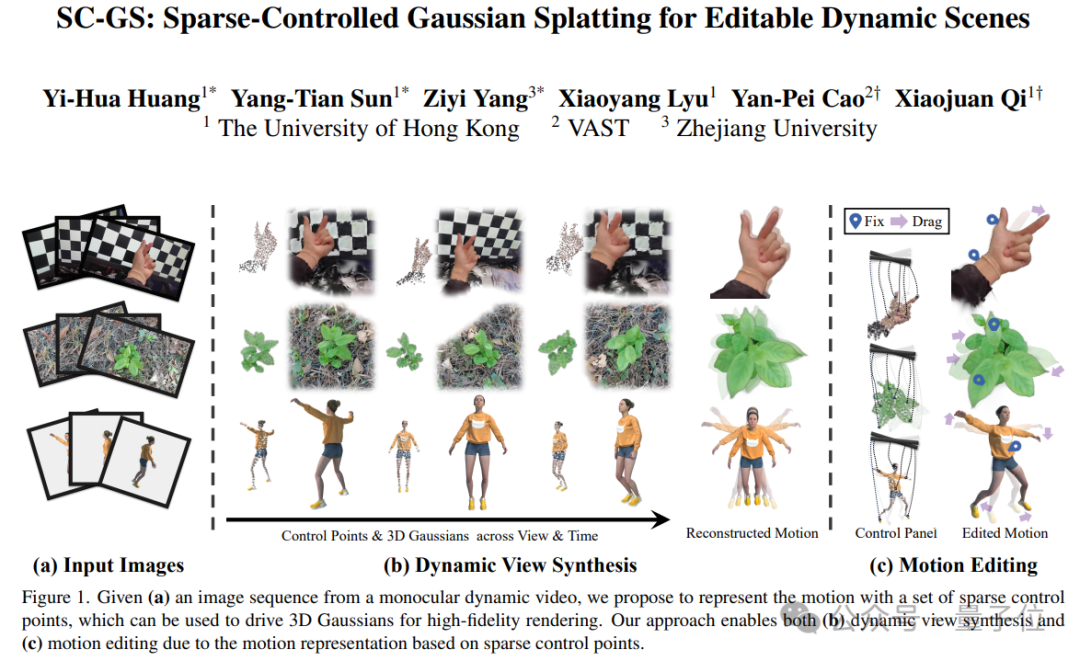
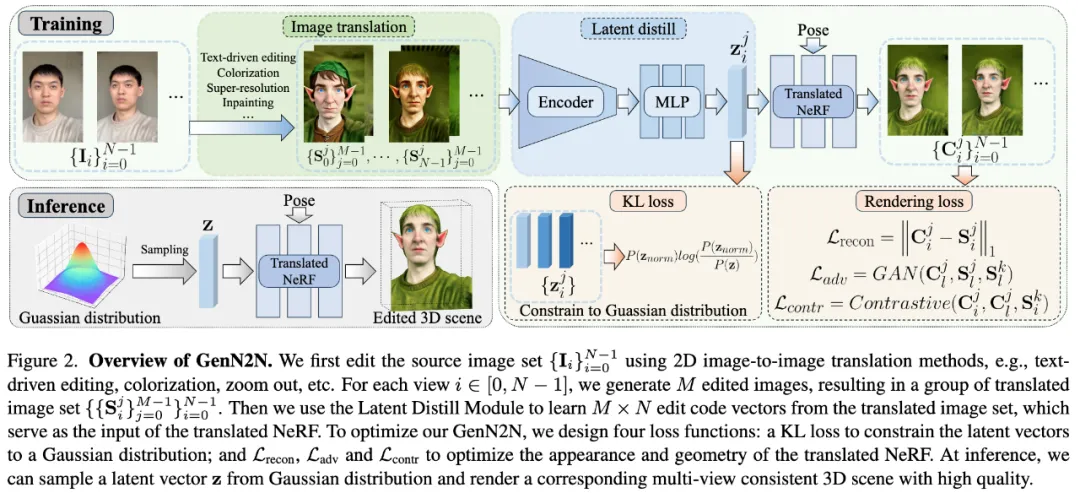
CVPR 2024 | 文本一键转3D数字人骨骼动画,阿尔伯塔大学提出MoMask框架
CVPR 2024 | 文本一键转3D数字人骨骼动画,阿尔伯塔大学提出MoMask框架想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视制作,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。
来自主题: AI技术研报
9489 点击 2024-04-29 20:45