扩散模型还原被遮挡物体,几张稀疏照片也能"脑补"完整重建交互式3D场景|CVPR'25
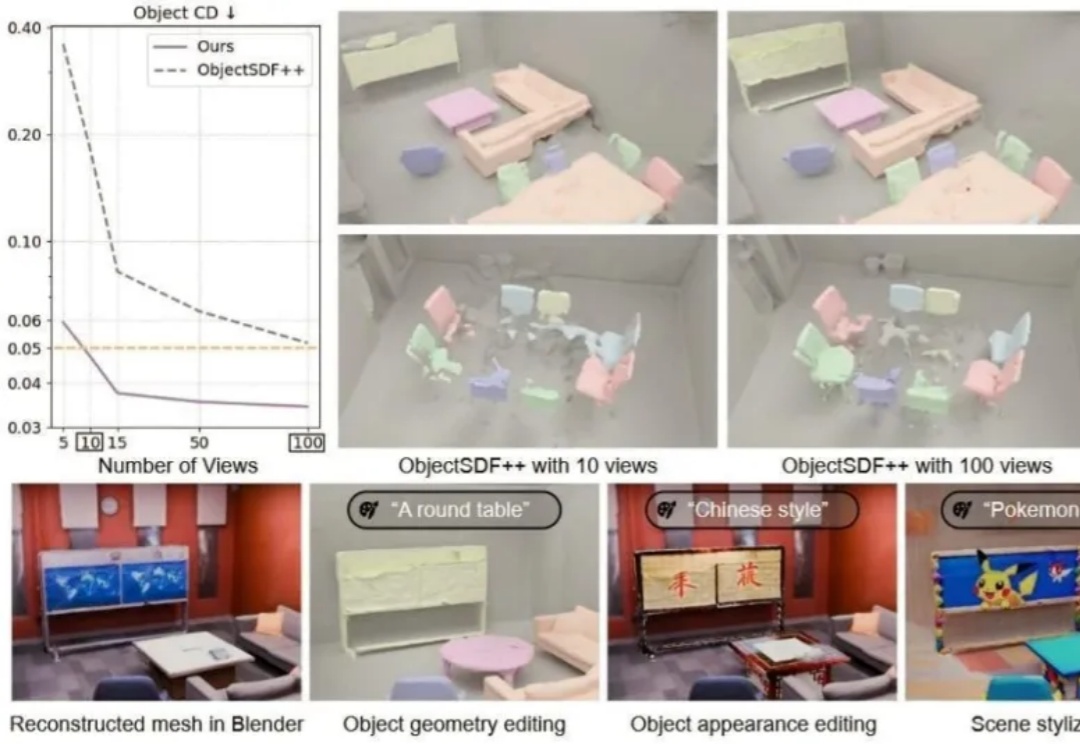
扩散模型还原被遮挡物体,几张稀疏照片也能"脑补"完整重建交互式3D场景|CVPR'25你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?
来自主题: AI技术研报
9590 点击 2025-04-23 15:03
 搜索
搜索
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?
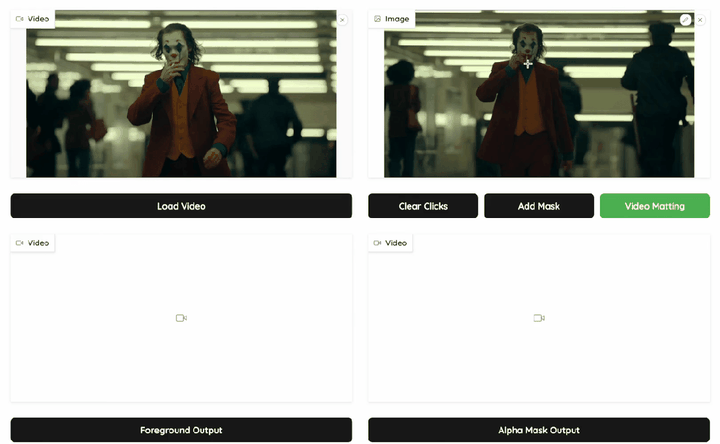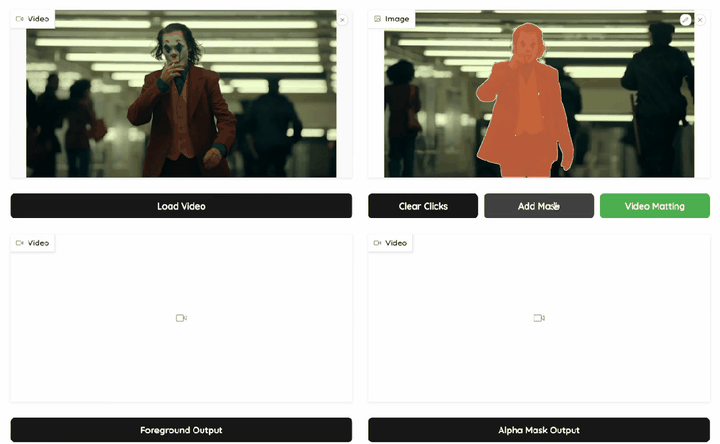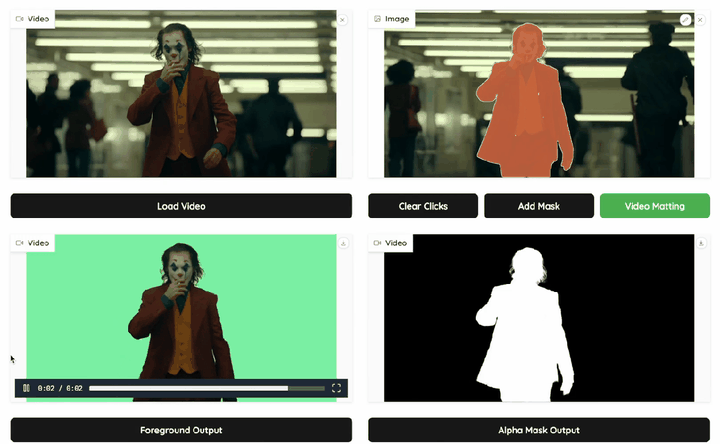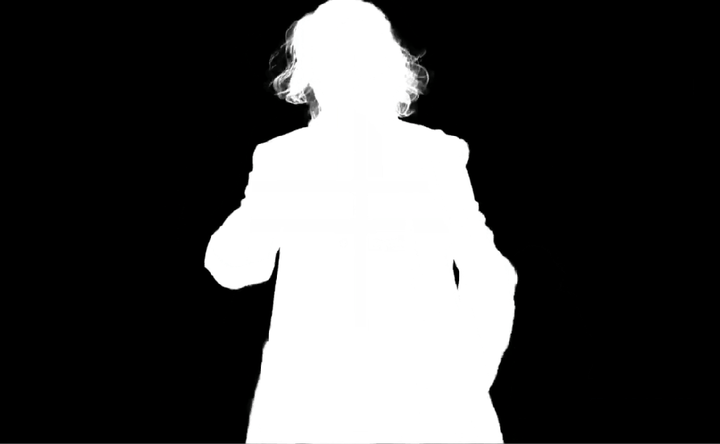
视频人物抠像技术在电影、游戏、短视频制作和实时视频通讯中具有广泛的应用价值,但面对复杂背景和多目标干扰时,如何实现一套兼顾发丝级细节精度及分割级语义稳定的视频抠图系统,始终是个挑战。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
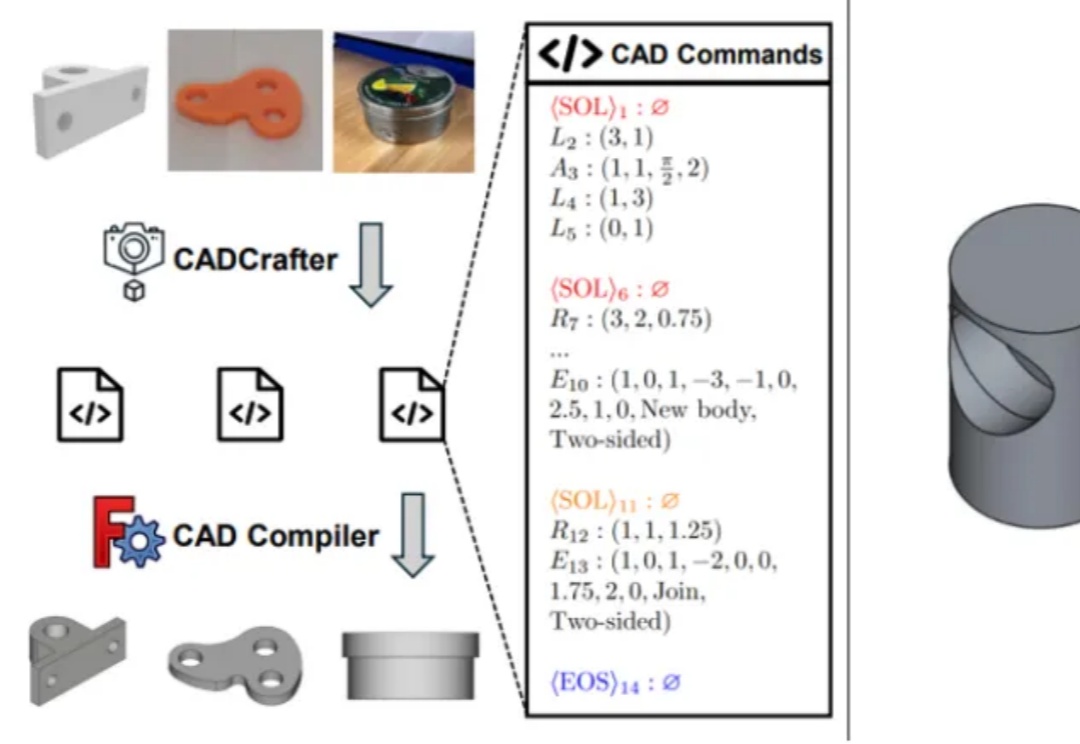
单张图直接就能生成可编辑的CAD工程文件!

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。

多模态视频异常理解任务,又有新突破!
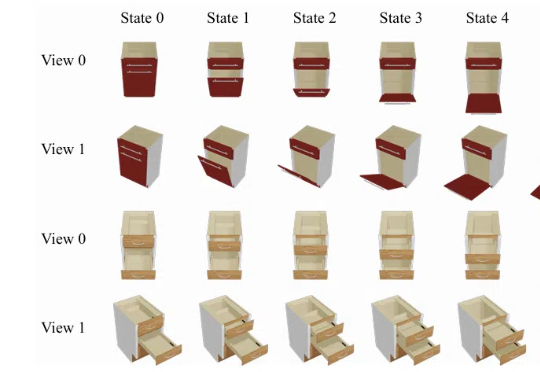
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。

想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。
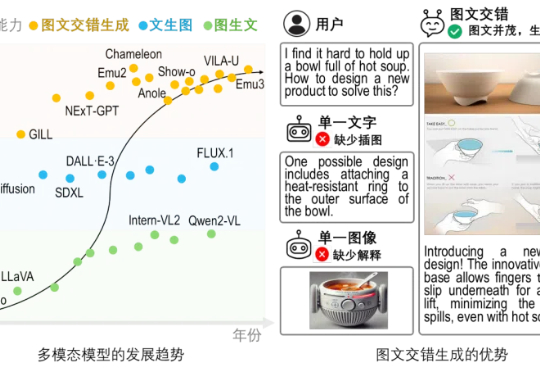
文生图 or 图生文?不必纠结了!