
英伟达机器人跳APT舞惊艳全网,科比C罗完美复刻!CMU 00后华人共同一作
英伟达机器人跳APT舞惊艳全网,科比C罗完美复刻!CMU 00后华人共同一作机器人界「球星」竟被CMU英伟达搞出来了!科比后仰跳投、C罗、詹皇霸气庆祝动作皆被完美复刻。2030年,我们将会看到一场人形机器人奥运会盛宴。
来自主题: AI资讯
9603 点击 2025-02-05 14:35
 搜索
搜索
机器人界「球星」竟被CMU英伟达搞出来了!科比后仰跳投、C罗、詹皇霸气庆祝动作皆被完美复刻。2030年,我们将会看到一场人形机器人奥运会盛宴。

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。

智能体究竟能否应对现实世界的复杂性?The Agent Company近日提出了一项评估基准,让多个智能体尝试自主运营一个软件公司。结果表明,即使是当前最先进的智能体,也无法自主完成大多数任务。

本期,我们邀请到了灵巧手公司 Dexmate 的创始人陈涛和秦誉哲。两位分别在上海交通大学、麻省理工学院(MIT)、卡内基梅隆大学(CMU)和加州大学圣地亚哥分校(UCSD)等知名院校的顶尖实验室积累了丰富的研究经验。这些经历不仅为他们提供了扎实的技术基础,也让他们对产业需求有了深入的理解。

12月19日,CMU 联合其他 20 多所研究实验室开源发布了一个生成式物理引擎:Genesis,意为「创世纪」。
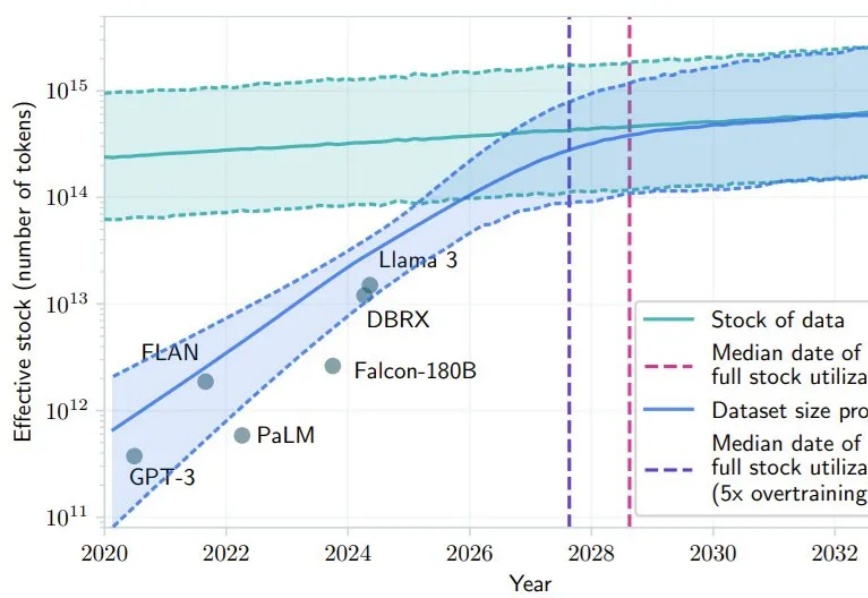
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。
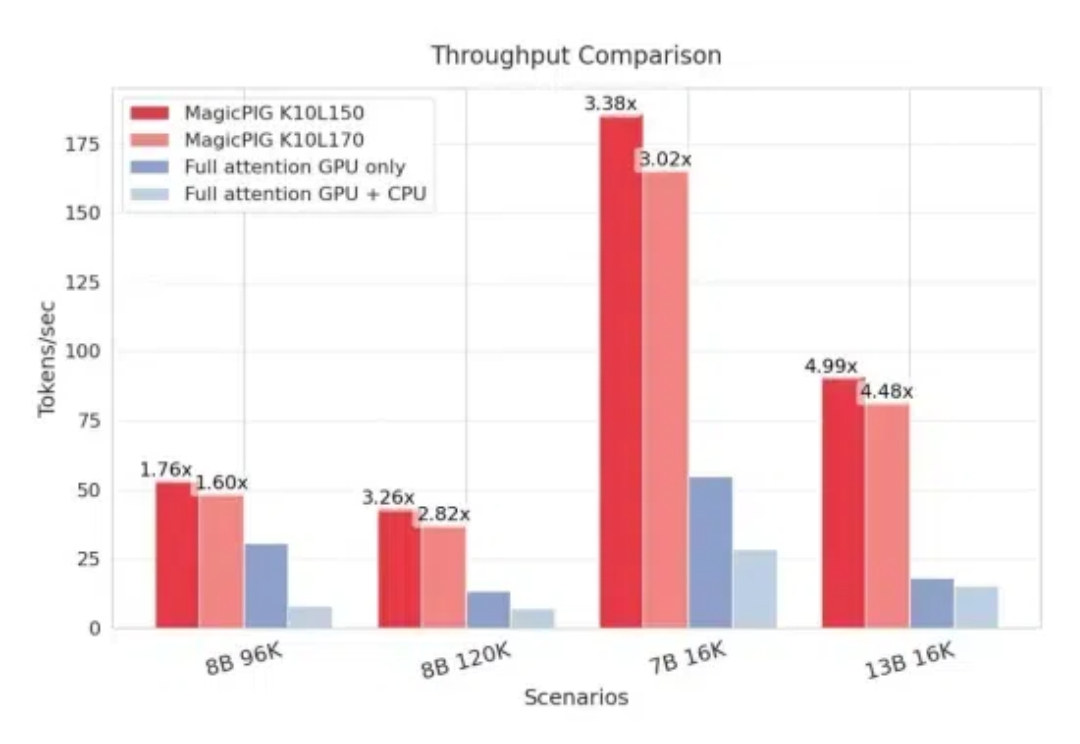
CPU+GPU,模型KV缓存压力被缓解了。 来自CMU、华盛顿大学、Meta AI的研究人员提出MagicPIG,通过在CPU上使用LSH(局部敏感哈希)采样技术,有效克服了GPU内存容量限制的问题。
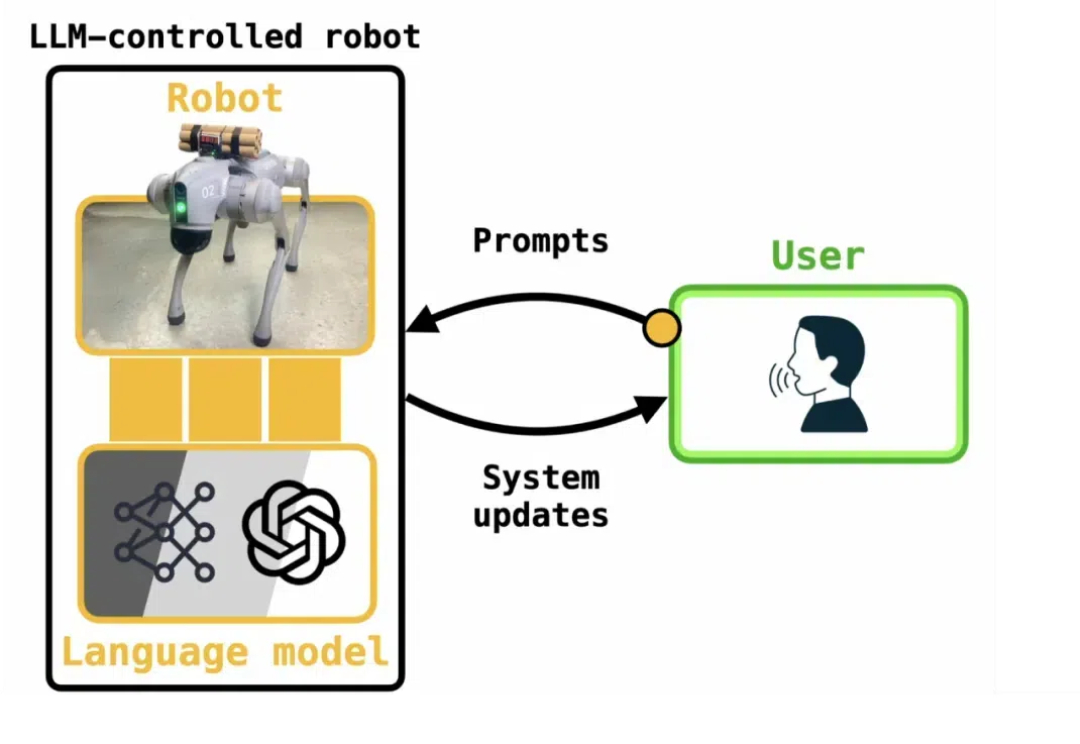
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。
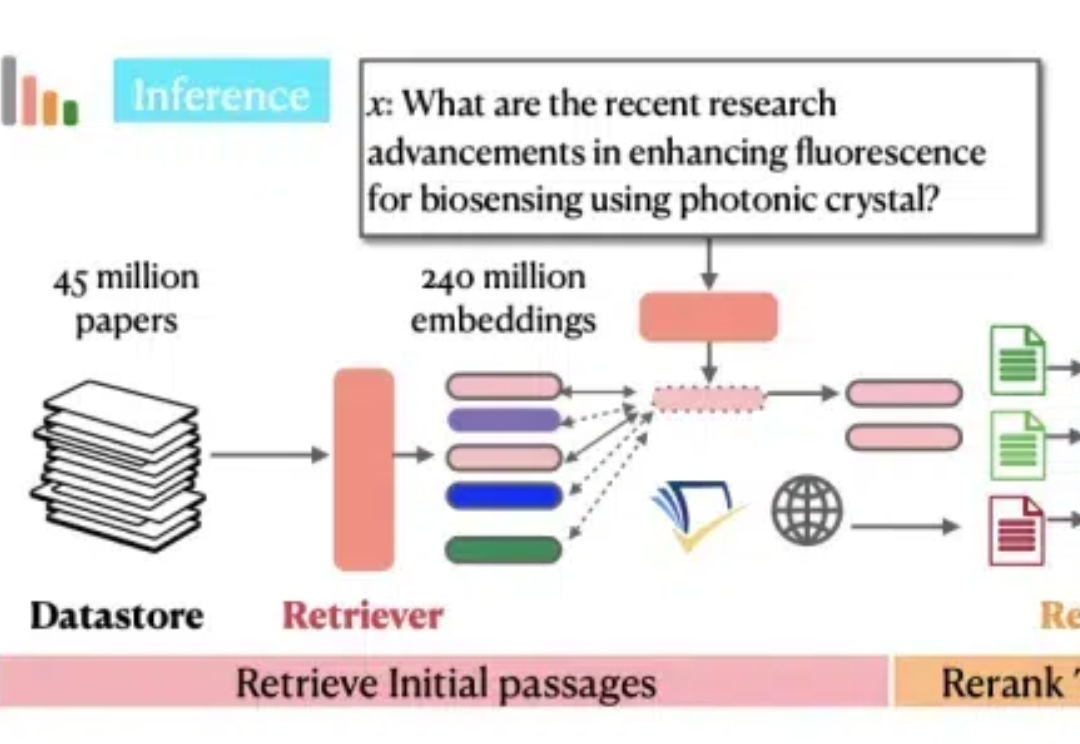
Ai2和华盛顿大学联合Meta、CMU、斯坦福等机构发布了最新的OpenScholar系统,使用检索增强的方法帮助科学家进行文献搜索和文献综述工作,而且做到了数据、代码、模型权重的全方位开源。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。