Mistral再开源!发布代码模型Devstral 2及原生CLI,但大公司被限制商用
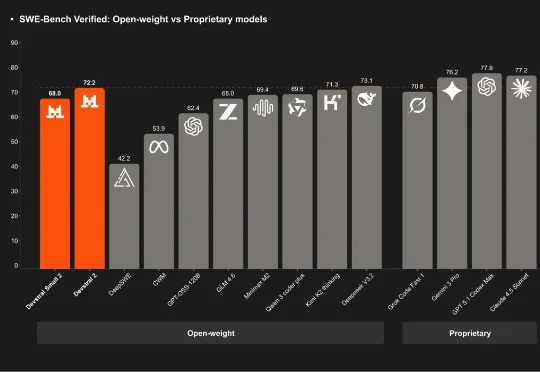
Mistral再开源!发布代码模型Devstral 2及原生CLI,但大公司被限制商用刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。
来自主题: AI资讯
9913 点击 2025-12-10 14:41